

A few years ago, I first came into contact with the natural language processing model BERT during a job.
When evaluating the performance of this model at that time, the leader said that the performance of this model needs to reach 200 tokens per second. Although he knew that this was a performance indicator, the concept of token was not very clear.
Because I had more exposure to visual models at that time, in the performance evaluation of visual models, there was a key indicator called fps, which is commonly understood as the number of pictures that can be processed in one second.
So what is the token per second? To understand this, we must first understand what a token is.
1. What is a token?
In the computer field, token usually refers to a string of characters or symbols. For example, the key of the WeChat public platform is called a token, which is actually a long string of characters.
In the field of artificial intelligence, especially in natural language processing (NLP), “token” refers to the smallest unit or basic element for processing text .
It can be a word, a phrase, a punctuation mark, a subword, or a character.
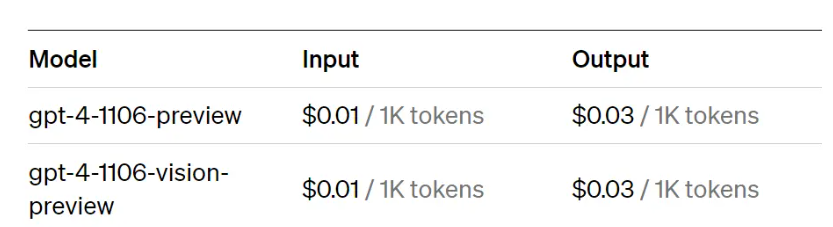
At present, many large models are based on tokens in terms of display capabilities and charging pricing. For example, OpenAI’s charging standard is: GPT-4, 1k tokens charge 0.01 knives.
So how to understand token?
Suppose you want an AI model to recognize the following sentence: “I love natural language processing!”.
The model does not directly understand what this sentence means, but needs to first decompose this sentence into token sequences.
For example, this sentence can be broken down into the following tokens:
- “I”
- “love”
- “natural”
- “language”
- “processing”
- “!”
The final punctuation mark is also a token, so what the model sees is the basic token unit, which helps the AI model understand the structure and meaning of the sentence.
2. How to split the token?
In NLP tasks, before processing text, the text needs to be tokenized, that is, the text is tokenized, and then these tokens are operated.
There are currently many algorithms that can complete this tokenization process, which will not be discussed here.
Seeing this, you may ask, isn’t a token just a word?
In fact, this is not the case. As we said above, a token can be a word, a phrase or some sub-words.
For example, in the tokenization stage, the three words “New York City” may be regarded as a token, because these three words together have a specific meaning, called New York City.
It is also possible to think of the word “debug” as two tokens, namely “de” and “bug”, so that the model may know that the “de” prefix means “reduce”.
If you encounter something like “devalue” again, you will divide it directly into two tokens, namely “de” and “value”, and you can know that devalue means “reduce value”.
Such tokens belong to subwords in words. This has many benefits. One of the benefits is that the model does not need to remember too many words.
(photo by AI)
Otherwise, the model may need to remember the four tokens “bug”, “debug”, “value”, and “devalue”.
Once the word is divided into sub-words, the model only needs to remember the three tokens “bug”, “value” and “de”, and it can also be extended to identify the meaning of “decrease”.
Do you understand after seeing this? A token may represent a word, a phrase, or characters and punctuation marks.
If you have an environment where chatGPT is used, you can test it to see if it can reverse the sentence.
In general, token can be understood as the smallest unit for natural language models to process text.
It is not necessarily a word, it may be a phrase, it may be some prefixes such as “de”, or it may be some punctuation (for example, an exclamation mark may represent stronger feelings), etc.
Knowing what token is, the meaning of token / s is very simple. This unit represents the number of tokens that the model can process in one second.
The larger the number, the faster the model processes text. Whether it is recognizing text or outputting text, it will be smoother for users to use it.