

Introduction
The phi-series model is a lightweight artificial intelligence model launched by the Microsoft research team. It aims to achieve the goal of being “small and precise” and can be deployed and run on low-power devices such as smartphones and tablets. So far, the phi-3 model has been released . This series of blogs will introduce it along the initial phi-1 to phi-1.5, and then to the phi-2 and phi-3 models. This article introduces the latest phi-3 model.
- Title: Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
- Link: arxiv.org/abs/2404.14…
Summary
This article introduces the Phi-3-mini model, which has 3.8B parameters and a training sample of 3.3T tokens. Its overall performance is comparable to models such as Mixtral 8x7B and GPT-3.5. The innovation of Phi-3 is entirely reflected in the data set used for training, which is an enlarged version of the data set used by phi-2 and consists of strictly screened network data and synthetic data. The model is further tuned for robustness, security, and chat format. This paper also provides some initial parameter scaling results using 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium respectively, both of which are more compact than phi-3-mini. powerful.
1 Introduction
The remarkable progress in artificial intelligence in recent years is largely due to the ever-increasing scale of models and data sets, with the size of large language models (LLMs) gradually increasing from a billion parameters just five years ago to a trillion parameters today. This effort is motivated by the seemingly predictable improvements obtained by training large models, the so-called scaling law. However, these laws assume a “fixed” data source. This assumption is now being significantly disrupted by cutting-edge LLMs themselves, models that enable researchers to interact with data in novel ways. Previous work on phi models showed that the combination of LLM-based filtering of network data and LLM-created synthetic data enables smaller language models to achieve levels of performance typically only seen in larger models. For example, a previous model using this data recipe, phi-2 (2.7B), matched the performance of a 25x larger model trained on conventional data. This report introduces a new model, phi-3-mini (3.8B), trained on 3.3T tokens on a larger, more advanced version of the dataset used in phi-2. Due to its small size, phi-3-mini can easily perform local inference on modern phones, but its quality appears to be on par with models such as Mixtral 8x7B and GPT-3.5.

2 Technical specifications
The Phi-3-mini model is a Transformer decoder architecture with a default context length of 4K. The author also introduces a long context version through LongRope that extends the context length to 128K, called phi-3-mini-128K.
To maximize the benefit of the open source community, phi-3-mini is built on a similar block structure as Llama-2 and uses the same tokenizer with a vocabulary of 32064. This means that all software packages developed for the Llama-2 series models can be directly adapted to the phi-3-mini. The model uses 3072 hidden dimensions, 32 heads and 32 layers. A total of 3.3T tokens were trained using BF16. The model has been fine-tuned for chat, and the chat template is as follows:

The Phi-3-small model (7B parameters) utilizes the tiktoken tokenizer (for better multilingual tokenization), has a vocabulary of 100352, and has a default context length of 8K. It follows the standard Transformer architecture of the 7B model class, with 32 layers and a hidden dimension of 4096. To minimize KV cache occupancy, the model also utilizes grouped query attention, where 4 queries share 1 key. Additionally, phi-3-small uses alternative layers of dense attention and novel block-sparse attention to further optimize KV cache savings while maintaining long context retrieval performance. This model also uses an additional 10% multilingual data.
High-performance language models running natively on mobile phones
Due to its small size, the phi-3-mini can be quantized to 4 bits and therefore only takes up about 1.8GB of memory. The author tested the quantitative model by running phi-3-mini locally on the iPhone 14 equipped with the A16 Bionic chip and deploying it completely offline (Figure 1), reaching more than 12 words per second.
training method
Following a line of work begun in “Textbooks Are All You Need”, we leverage high-quality training data to improve the performance of small language models and deviate from standard scaling laws. This paper shows that this approach can bring a model with a total parameter of only 3.8B to a level comparable to high-performance models such as GPT-3.5 or Mixtral (for example, Mixtral has a total parameter of 45B). The training data for this article consists of strictly filtered network data (according to “education level”) from various open Internet sources as well as data generated by synthetic LLM. Pre-training is divided into two disjoint and sequential stages; the first stage mainly consists of network sources and is designed to teach the model general knowledge and language understanding capabilities. The second phase combines more rigorously filtered network data (the subset used in the first phase) with some synthetic data that teaches the model logical reasoning and various professional skills.
data optimal mode
Unlike previous methods of training language models in “computationally optimal mode” or “overtraining mode”, this article focuses on the quality of data at a given scale. The authors attempt to calibrate the training data to a state closer to the “data-optimal” mode for small models. In particular, filter web data to contain the correct “knowledge level” and retain more web pages that are likely to improve the model’s “reasoning power.” For example, the Premier League match results on a given day might be good training data for a cutting-edge model, but this paper needs to remove this information to leave more model capacity for “inference” of small models. The comparison between Phi-3 and Llama-2 is shown in Figure 2.

In order to test the data of this article on a larger model, the author also trained phi-3-medium, a model with 14B parameters, using the same tokenizer and architecture as phi-3-mini, and slightly more The same data is used for training on rounds (a total of 4.8T tokens, the same as phi-3-small). The model has 40 heads and 40 layers with an embedding dimension of 5120. It can be observed that the improvement from 7B to 14B for some benchmarks is much less than the improvement from 3.8B to 7B, which may indicate that our data blending needs further work to adapt to the “data optimal mode” of the 14B parameter model. The authors are still actively investigating some of these benchmarks (including regression on HumanEval), so the performance of phi-3-medium should be considered a “preview”.
Post-training
The post-training of Phi-3-mini goes through two stages, including supervised fine-tuning (SFT) and direct preference optimization (DPO). SFT leverages highly curated, high-quality data across multiple domains such as mathematics, coding, reasoning, conversation, model identity, and security. SFT Data Mixing starts with an English-only example. DPO data covers chat format data, inference and responsible AI (RAI) efforts. The authors use DPO to guide the model away from bad behavior by using these outputs as “reject” responses. In addition to improvements in mathematics, coding, reasoning, robustness, and security, post-training turns language models into AI assistants that users can interact with efficiently and safely.
As part of the post-training process, the authors developed a long context version of phi-3-mini, extending the context length limit to 128K instead of 4K. Overall, the 128K model is of comparable quality to the 4K length version while being able to handle long context tasks. Long context expansion is divided into two stages, including long context mid-training and long-short hybrid post-training, both of which include SFT and DPO.
3 Academic Benchmarks
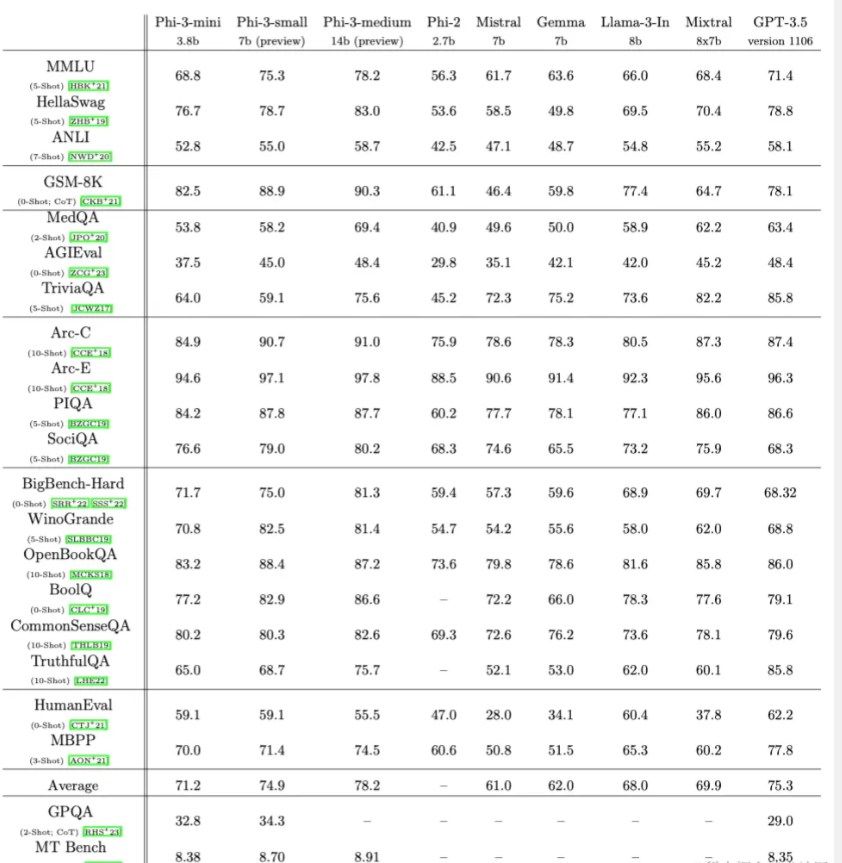
The results of phi-3-mini on standard open source benchmarks, which are used to measure the model’s reasoning capabilities (including common sense reasoning and logical reasoning), are as follows.
4 Security
Phi-3-mini was developed in line with Microsoft’s Principles for Responsible Artificial Intelligence. The overall approach includes security alignment, red team testing, automated testing and assessment in post-training, covering dozens of responsible AI hazard categories. The authors utilize helpful and harmless preference datasets as well as multiple internally generated datasets and modify them to address responsible AI hazard categories in safe post-training. An independent red team at Microsoft conducted iterative inspections of phi-3-mini during the post-training process to further identify directions for improvement. Based on their feedback, this paper curated additional datasets to address their insights, thereby refining the post-training dataset. This process resulted in a significant reduction in harmful response rates, as shown in Figure 3.
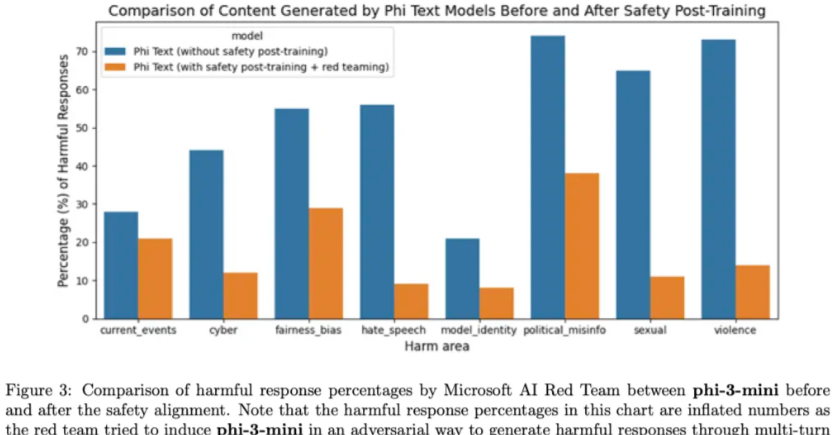
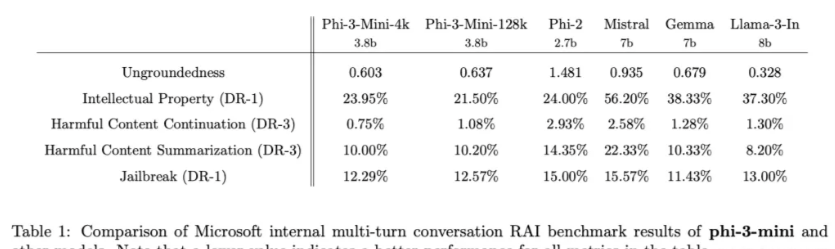
Table 1 shows the internal Responsible Artificial Intelligence benchmark results for phi-3-mini-4k and phi-3-mini-128k. This benchmark utilizes GPT-4 to simulate multiple rounds of conversations across five different categories and evaluate the model’s response. Non-factuality, between 0 (completely fact-based) and 4 (not fact-based), measures whether the information in the response is based on the given prompt. In other categories, responses are evaluated according to harmfulness severity from 0 (harmless) to 7 (extremely harmful), and the defect rate (DR-x) is calculated as the percentage of samples with a severity score greater than or equal to x.

5 weaknesses
In terms of language model capabilities, although the phi-3-mini model has reached a level similar to larger models in terms of language understanding and reasoning capabilities, it is still basically limited by its size for certain tasks. For example, the model’s poor performance on TriviaQA can be seen as it simply does not have enough capacity to store too much “factual knowledge”. The author believes this weakness can be addressed through enhancements with search engines. Figure 4 shows an example of using HuggingFace’s default Chat-UI and phi-3-mini. Another weakness related to model capacity is that currently the language is mainly limited to English. Exploring the multilingual capabilities of small language models is a future research direction.
Despite the authors’ serious responsible AI efforts, as with most language models, there remain challenges regarding factual inaccuracies (or hallucinations), reproduction or amplification of bias, inappropriate content generation, and safety concerns. The use of carefully curated training data, along with targeted post-training and improvements from red team insights, significantly mitigates these issues across all dimensions. However, fully addressing these challenges still requires a lot of work.