


Chart 1: General training process for large models[1]
In the frontier field of artificial intelligence, Large Language Models (LLMs) are attracting the attention of researchers around the world due to their powerful capabilities. In the R&D process of LLMs, the pre-training stage occupies a pivotal position. It not only consumes a large amount of computing resources, but also contains many secrets that have not yet been revealed. According to research by OpenAI, during the development process of InstructGPT, the pre-training phase almost exhausted all computing power and data resources, accounting for as high as 98% [2] .
Diagram 2: Shoggoth with a smiling face[3]
The pre-trained model is like a raw but powerful beast. After going through a long pre-training phase, the model has modeled a large amount of rich world knowledge. With the help of high-quality dialogue data for Supervised Fine-Tuning (SFT), we can make this “beast” understand human language and adapt to social needs; and then through Reinforcement Learning with Human Feedback , RLHF), so that it can more accurately meet the personalized demands of users, “align” with human beings in terms of values, and thus be able to better serve society. Related alignment stages, such as SFT and RLHF, can be viewed as a process of taming this beast. But our goal is more than that, and more importantly, it is to reveal the fundamental process that gives LLMs unique capabilities – the Pre-training Period. The pre-training stage is like a treasure box containing infinite possibilities, and researchers urgently need to dig deeper into its more profound values and operating mechanisms.
Currently, most open source LLMs only publish model weights and performance indicators, while in-depth understanding of model behavior requires more detailed information. The comprehensive open source of LLM360 [4] and OLMo [5] provides researchers and the community with a full range of in-depth analysis including training data, hyperparameter configuration, multiple model weight slices in the pre-training process, and performance evaluation, which greatly It enhances the transparency of the LLMs training process and helps us understand its operating mechanism.
Can humans trust LLMs? Faced with this core issue, Shanghai AI Lab, Renmin University of China, University of Chinese Academy of Sciences and other institutions started from the pre-training stage to try to gain insight into the behemoth of LLMs. The team is committed to analyzing how LLMs build trustworthy related concepts (Trustworthiness) in the pre-training phase, and trying to explore whether the pre-training phase has the potential to guide and improve the trustworthiness of the final LLMs.

- Paper title: Towards Tracing Trustworthiness Dynamics: Revisiting Pre-training Period of Large Language Models
- Paper link: arxiv.org/abs/2402.19…
- Project homepage: github.com/ChnQ/Tracin…
This work gives for the first time the following observations:
- It was found that LLMs established linear representations of credible concepts in the early stages of pre-training and were able to distinguish credible and uncredible inputs ;
- It was found that during the pre-training process, LLMs showed a learning process similar to “information bottleneck” for trusted concepts, first fitting and then compressing ;
- Based on representation intervention technology, it was initially verified that slicing of LLMs during the pre-training process can help improve the trustworthy capabilities of the final LLMs .
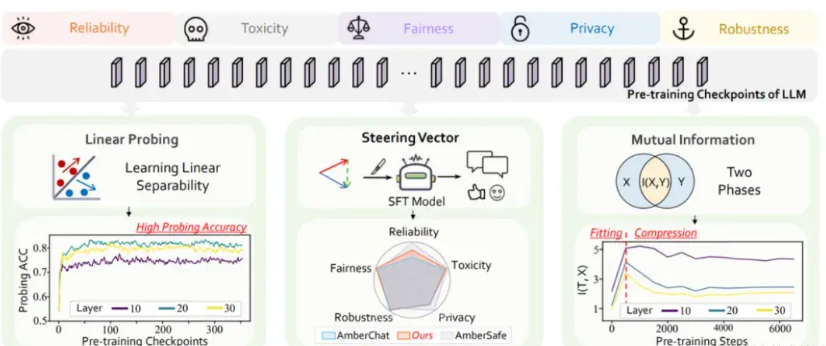
Chart 3: Article overview chart
In this study, the team used the rich LLM pre-training resources provided by the LLM360 [4] open source project. The project pre-trained its basic 7B model Amber with 1.3 trillion Tokens pre-training data, and evenly open sourced 360 model parameter slices in the pre-training process. In addition, based on Amber, LLM360 further released two fine-tuned models: the AmberChat model optimized using instruction fine-tuning and the AmberSafe model optimized for safety alignment.
1 LLMs quickly build linear representations of credible concepts during pre-training
**Dataset:** This article mainly explores five key dimensions in the field of trust: reliability, toxicity, privacy, fairness and robustness. Under each dimension, the team selected representative relevant data sets to assist research: TruthfulQA, Toxicity, ConfAIde, StereoSet and SST-2 processed with specific perturbations. The team labels each sample based on the settings of the original data set to identify whether each input sample contains incorrect, toxic, privacy leaking, discriminatory and disturbed information.
**Experimental Settings:** This paper uses Linear Probing technology [6] to quantify how well the internal representations of LLMs model trusted concepts.
Specifically, for a data set under a certain credible dimension, the team collects the internal representation of all slices under the data set, trains a linear classifier for each layer of representation of each slice, and the linear classifier is used on the test set The accuracy of represents the ability of the model’s internal representation to distinguish different credible concepts. The experimental results of the first 80 slices are as follows (for subsequent experimental results of complete slices, please refer to the appendix of the text, the experimental trends are generally the same):
Figure 4: Line probe experimental results
The experimental results shown in the figure above show:
- As pre-training proceeds, on the five selected credibility dimensions, the representation of the middle layer of the large model can well distinguish whether it is credible or not;
- For distinguishing whether a sample is credible or not, large models quickly learn relevant concepts in the early stages of pre-training (the first 20 slices).
2 Examining the pre-training dynamics of LLMs regarding trustworthy concepts from the perspective of information bottlenecks
Inspired by the use of mutual information to detect dynamic changes in the model during the training process [7] , this paper also uses mutual information to conduct a preliminary exploration of the dynamic changes in LLMs representation during the pre-training process. The team drew on the method of using information plane to analyze the traditional neural network training process in [7] , and respectively explored the mutual information between the model representation T and the five original data sets X, as well as the relationship between the model representation T and the data set label Y. mutual information. Among them, the experimental results in the Reliability dimension are as follows (for experimental results in other credibility dimensions, please refer to the appendix of the original article):
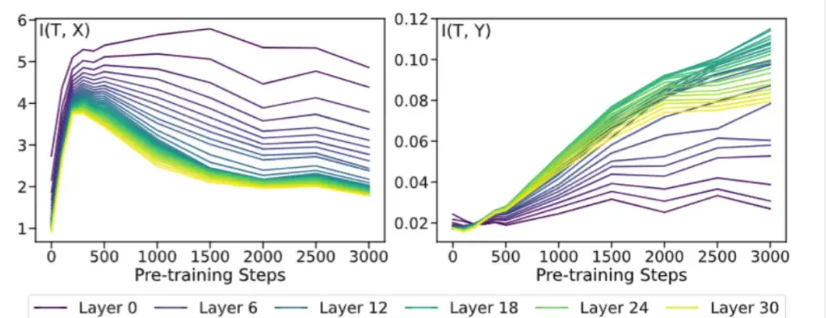
Figure 5: Mutual information experimental results
It can be seen from the figure that the mutual information between T and X shows a trend of rising first and then falling, while the mutual information between T and Y continues to rise. Taken together, the team found that** these trends are consistent with the two stages of “fitting” and then “compression” described in the classic paper [7] . **Specifically, large language models do not have the ability to retain information during initial randomization, so the mutual information is close to 0; as pre-training proceeds, large models gradually have the ability to understand language and concept modeling, so Mutual information continues to grow; with further pre-training, the large model gradually learns to compress irrelevant information and extract effective information, so the mutual information of T and X decreases, while the mutual information of T and Y continues to grow.
From a mutual information perspective, this is an interesting finding. Although there are subtle differences in definitions and experimental settings, the pre-training stages of both large language models and traditional neural networks can be divided into two stages: “fitting” and “compression”. This implies that there may be something in common between the training processes of large language models and traditional neural networks. This discovery not only enriches the team’s understanding of the dynamics of large model pre-training, but also provides new perspectives and ideas for future research.
3 How pre-training slices help improve the credibility of final LLMs
3.1 Characterization intervention techniques
The team observed that since LLMs have learned linearly separable representations of trusted concepts in the early stages of their pre-training, a natural question is: can the slicing of LLMs during the pre-training process help the final instruction fine-tuning? How about aligning the model (SFT model)?
The team gave a preliminary affirmative answer to this question based on the technology of characterization intervention (Activation Intervention).
Activation Intervention is a rapidly emerging technology in the field of LLMs and has been proven effective in multiple scenarios [8-9] . Here, we take how to alleviate the hallucination problem of LLMs and make its answers more “real” as an example [8] to briefly explain the basic process of characterization intervention technology:
1. First, use positive and negative texts covering real and false information to stimulate LLMs and collect their corresponding internal representations;
2. Then, make a difference between the centroids of the positive and negative representations to obtain the “steering vector pointing in the true direction (Steering Vector)”;
3. Finally, add the guidance vector to the representation generated at each step of LLMs forward reasoning to achieve the purpose of intervening in the output.
Different from the above method, which extracts the guidance vector from the model itself to be intervened, the team intends to construct the guidance vector from the slices of the LLMs pre-training process to intervene in the instruction fine-tuning model, as shown in the figure below.
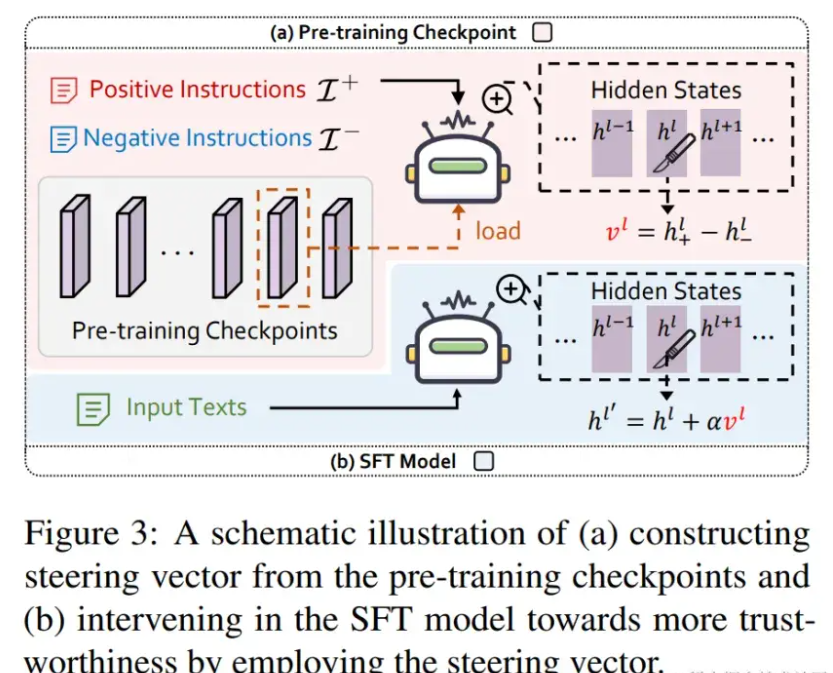
Figure 6: Schematic diagram of characterization intervention technology
Among them, the team used the PKU-RLHF-10K data set [10-11] open sourced by the Peking University team to construct positive and negative text pairs. This data set contains 10,000 conversation data with safe/non-safe reply annotations and can be used for LLMs RLHF training.
3.2 Analysis of experimental results
The paper uses five-dimensional data sets in the trust field mentioned above (Reliability: TruthfulQA, Toxicity: Toxigen, Fairness: StereoSet, Privacy: ConfAIde, Robustness: SST-2), as well as four commonly used large model general capabilities On the evaluation data set (MMLU, ARC, RACE, MathQA), the performance of four models was evaluated: the instruction fine-tuning model AmberChat, the safety alignment model AmberSafe, the AmberChat after intervention using the guidance vector from AmberChat itself, and the use of intermediate pre-training slices AmberChat after the intervention of bootstrapping vectors. The experimental results are shown in the figure below (for more experimental observation results, please go to the original text):
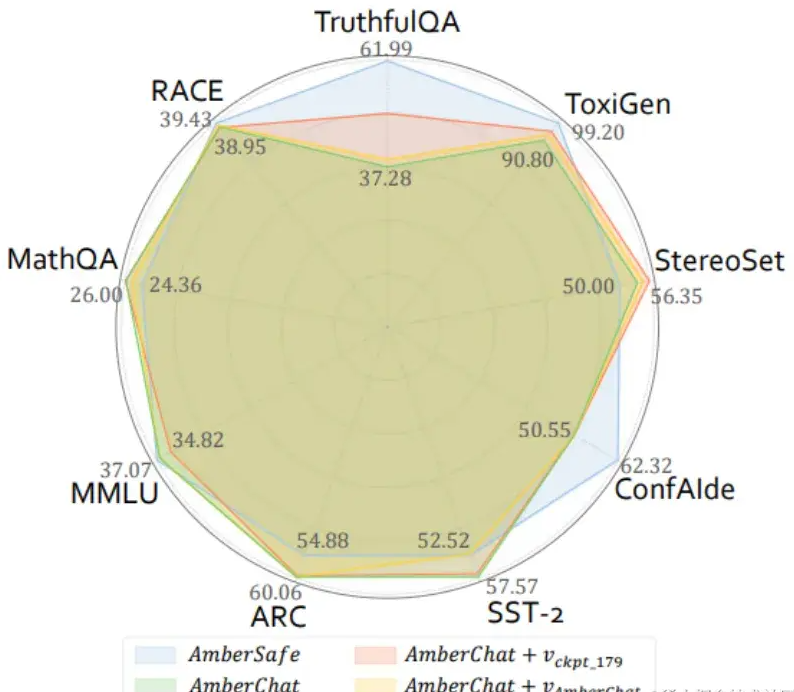
Figure 7: Characterizing the model performance evaluation results after intervention
Experimental results show that after using the guidance vectors from pre-trained slices to intervene in AmberChat, AmberChat has significant improvements in three trustworthy dimensions (TruthfulQA, Toxigen, StereoSet). At the same time, the impact of this intervention on the general ability of the model is not significant (marginal loss on ARC, MMLU, and marginal improvement on MathQA and RACE).
Surprisingly, bootstrapping vectors constructed using pre-trained intermediate slices can significantly improve the trustworthy performance of the AmberChat model compared to bootstrapping vectors from AmberChat itself.
4 Summary
With the continuous advancement of artificial intelligence technology, in the future, when trying to align models that are more powerful than humans (Superalignment), traditional fine-tuning techniques that rely on “human feedback”, such as RLHF, may no longer work [12-13] . To address this challenge, research institutions are actively exploring new solutions. For example, OpenAI proposed a “weak versus strong supervision” method [12] , and Meta proposed a “self-reward” mechanism [13] . At the same time, more and more research has begun to pay attention to the emerging field of “self-alignment” [14-15] .
This research provides a new perspective for solving the Superalignment problem: **Utilizing slices of LLMs in the pre-training process to assist in the final model alignment. **The team first explored how LLMs construct and understand the concept of “credibility” during the pre-training process: 1) It was observed that LLMs have already modeled linear representations of the concept of credibility in the early stages of pre-training; 2 ) found that LLMs present an information bottleneck-like phenomenon in the process of learning trusted concepts. In addition, by applying representation intervention technology, the team preliminarily verified the effectiveness of slicing during the pre-training process in assisting the final LLMs alignment.
The team expressed the hope that this research can provide a new perspective for a deep understanding of how LLMs dynamically construct and develop their inherent trustworthy properties, and inspire more innovative attempts in the field of LLMs alignment technology in the future. At the same time, it is expected that these research results will help promote the development of LLMs in a more credible and controllable direction, and contribute a solid step to the field of artificial intelligence ethics and safety.
references
[3] twitter.com/anthrupad
[4] Liu, Z., Qiao, A., Neiswanger, W., Wang, H., Tan, B., Tao, T., … & Xing, EP (2023). Llm360: Towards fully transparent open -source llms. arXiv preprint arXiv:2312.06550.
[5] Groeneveld, D., Beltagy, I., Walsh, P., Bhagia, A., Kinney, R., Tafjord, O., … & Hajishirzi, H. (2024). OLMo: Accelerating the Science of Language Models. arXiv preprint arXiv:2402.00838.
[6] Belinkov, Y. (2022). Probing classifiers: Promises, shortcomings, and advances. Computational Linguistics, 48 (1), 207-219.
[7] Shwartz-Ziv, R., & Tishby, N. (2017). Opening the black box of deep neural networks via information. arXiv preprint arXiv:1703.00810.
[8] Li, K., Patel, O., Viégas, F., Pfister, H., & Wattenberg, M. (2024). Inference-time intervention: Eliciting truthful answers from a language model. Advances in Neural Information Processing Systems, 36.
[9] Turner, A., Thiergart, L., Udell, D., Leech, G., Mini, U., & MacDiarmid, M. (2023). Activation addition: Steering language models without optimization. arXiv preprint arXiv: 2308.10248.
[10] Ji, J., Liu, M., Dai, J., Pan, X., Zhang, C., Bian, C., … & Yang, Y. (2024). Beavertails: Towards improved safety alignment of llm via a human-preference dataset. Advances in Neural Information Processing Systems, 36.
[11] huggingface.co/datasets/PK…
[12] Burns, C., Izmailov, P., Kirchner, JH, Baker, B., Gao, L., Aschenbrenner, L., … & Wu, J. (2023). Weak-to-strong generalization : Eliciting strong capabilities with weak supervision. arXiv preprint arXiv:2312.09390.
[13] Yuan, W., Pang, RY, Cho, K., Sukhbaatar, S., Xu, J., & Weston, J. (2024). Self-rewarding language models. arXiv preprint arXiv:2401.10020.
[14] Sun, Z., Shen, Y., Zhou, Q., Zhang, H., Chen, Z., Cox, D., … & Gan, C. (2024). Principle-driven self- alignment of language models from scratch with minimal human supervision. Advances in Neural Information Processing Systems, 36.
[15] Li, X., Yu, P., Zhou, C., Schick, T., Levy, O., Zettlemoyer, L., … & Lewis, M. (2023, October). Self-Alignment with Instruction Backtranslation. In The Twelfth International Conference on Learning Representations.