

RAG is currently the most popular way to supplement generative artificial intelligence models. Recently, the pioneers of RAG have proposed a new contextual language model (CLM), which they call ” RAG 2.0 “.
Today, let us start from the current principles and shortcomings of RAG to see whether their proposed RAG2.0 can bring new hope to the industry.

Time validity of LLM
You should know that all standalone large language models (LLMs) (e.g. ChatGPT, etc.) have knowledge cutoffs.
This means that pre-training is a one-time exercise (unlike continuous learning methods). In other words, the data held by LLM is from a certain point in time.
For example, at the time of writing, ChatGPT was updated to April 2023. Therefore, they are not prepared to answer the facts and events that occurred after that date.
And this is where RAG comes into play.
semantic similarity
As the name suggests, the idea is to retrieve data from a known database that the LLM has never seen before and feed it into the model in real time so that it has updated, semantically relevant context to provide accurate Answer.
But how does this retrieval process work?
The entire architecture stems from one principle: the ability to retrieve semantically meaningful data relevant to the request or prompt context.
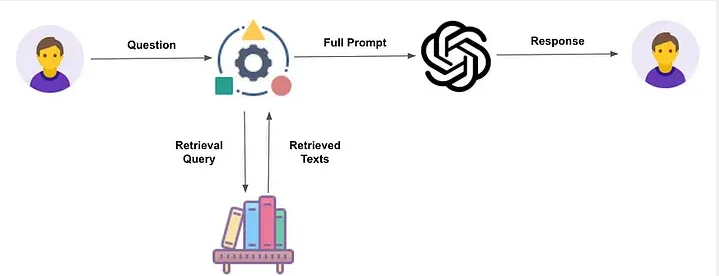
This process involves the use of three elements:
- embedding model
- retriever, usually a vector database
- And the generator, LLM
First and foremost, in order for this retrieval process to work properly, you need to embedding, i.e. numerically vectorize, your data.
More importantly, these embeddings adhere to the similarity principle: similar concepts will have similar vectors.
After completing the embeddings, we insert them into the vector database (retrieval).
Apply the principle of similarity
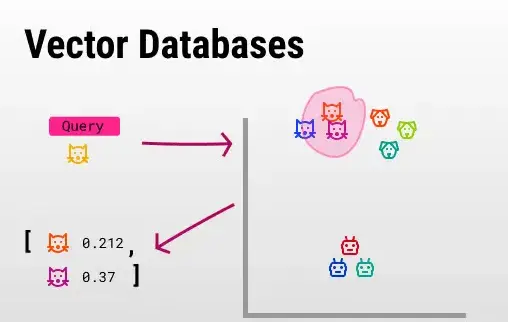
Then, * the vector database performs a “semantic query” every time a user sends a request like * “Give me results similar to ‘yellow cat'”.
In layman’s terms, it extracts the closest vector (distance) to the user’s query.
Since these vectors represent basic concepts, similar vectors will represent similar concepts, in this case other cats.
Once we have extracted the content, we build the LLM prompt, the package includes:
- User’s request
- Extracted content
- Generally speaking, there is also a set of system instructions
In a nutshell, this is RAG, a system that provides relevant content to users’ real-time queries to enhance LLM response.
The RAG system works in the first place thanks to LLM’s greatest superpower: contextual learning, which allows the model to perform accurate predictions using previously unseen data without the need for weight training.
But the process sounds too good to be true, and of course, things aren’t as amazing as they seem.
RAG’s Problem: Stitch Monster
A vivid metaphor for the former RAG system is the following pants:
While these pants may be suitable for a certain audience, most people will never wear them because there is no uniformity, despite the original intention of the patching being to be acceptable.
The reasoning behind this analogy is that the standard RAG system assembles three different components that are pretrained separately and, by definition, should never be combined together.
In the RAG 2.0 system, it is defined as “one thing” from the beginning.
RAG2.0
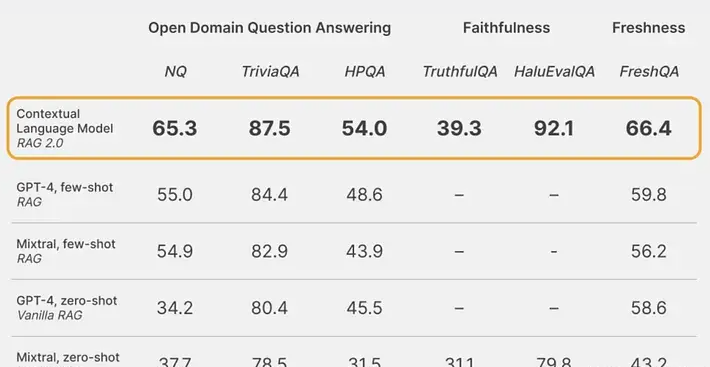
We compared a contextual language model (CLM) with a frozen RAG system across multiple axes:
- Open Domain Question Answering: We use the canonical Natural Questions (NQ) and TriviaQA datasets to test each model’s ability to correctly retrieve relevant knowledge and accurately generate answers. We also evaluate the model on the HotpotQA (HPQA) dataset in a single-step retrieval setting. All datasets use the exact match (EM) metric.
- Fidelity: HaluEvalQA and TruthfulQA are used to measure each model’s ability to maintain illusions based on retrieved evidence.
- Freshness: We use a web search index to measure each RAG system’s ability to generalize to rapidly changing world knowledge and show accuracy on the recent FreshQA benchmark.
The core innovation of RAG 2.0 lies in its end-to-end optimized design, which treats the language model and retriever as a whole for training and fine-tuning. This design not only improves the model’s accuracy on specific tasks, but also improves its ability to adapt to new problems, allowing it to reach unprecedented performance levels in multiple standard tests.
Compared with traditional RAG systems, RAG 2.0 is able to handle knowledge-intensive tasks more efficiently because it is not restricted by exposure to materials during training. By dynamically retrieving external sources such as Wikipedia, Google or internal company documents, RAG 2.0 is able to obtain and leverage the latest, most relevant information to enhance the accuracy and reliability of its answers.
In practice, the entire system is trained end-to-end while connected, as is the assumption that the LLM should always have a vector database tied to it to keep updated.
This means that during backpropagation, the algorithm that trains these models, the gradients are propagated not only through the entire LLM, but also through the retriever, so that the entire system as a whole learns from the training data.

The results also prove this:
Although the stand-alone model used is certainly worse than GPT-4, this new approach outperforms all other RAG 1.0 combinations between GPT-4 and other retrieval systems.
The reason is simple: in RAG 1.0, we trained things individually, then stitched them together and hoped for the best. But in RAG 2.0, things are very different because all components are together from the start.
But while the advantages of RAG 2.0 are clear, there’s still a big problem.
RAG’s future faces challenges
Although RAG 2.0 may appear to bring huge benefits** because it is designed specifically for companies unwilling to share confidential data with LLM providers, in reality its implementation faces huge challenges . **
Very long context
I’m sure you’re very aware of the fact that our cutting-edge models today, models like Gemini 1.5 or Claude 3, have huge context windows, up to 1 million tokens (750,000 words) in their production-released models , and in the laboratory it reached 10 million tokens (7.5 million words) .
In layman’s terms, this means that these models can be fed very long sequences of text per prompt.
For reference, the Lord of the Rings books have a total of 576,459 words, while the entire Harry Potter saga has approximately 1,084,170 words. So a 7.5 million-word contextual window could tie together two stories in each prompt, five times over.
In this case we really need a knowledge base retriever instead of just providing the information in every prompt
One reason to abandon this option might be accuracy. The longer the sequence, the harder it is for the model to retrieve the correct context, right?
The RAG process, on the other hand, allows selecting only semantically relevant data instead of providing the entire context in each prompt, making it a more efficient process overall.
However, the research is going on in the ultra-long context and LLM work has also shown almost 100% accuracy.
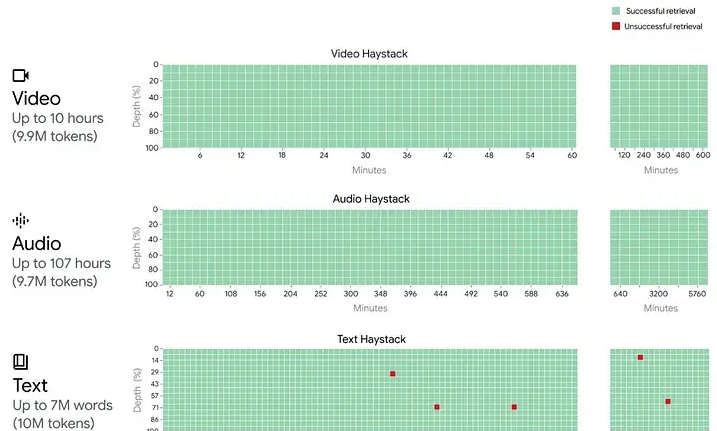
The technical support behind the amazing performance of these models regardless of length is that the basic operator of these models – the attention mechanism – has absolute global context, because the attention mechanism forces each individual order in the sequence to card (that is, a word or subword) to focus on every other preceding word in the sequence.
This ensures that no matter how distant the dependency is, and no matter how small the signal (critical information may be stored in a single word millions of words away), the model should be able to – and does – detect it.
Therefore, in my opinion, the ultimate survival of RAG does not depend on accuracy, but on another key factor besides technology:
cost.
Commercial implementation is needed to verify
Nowadays, since the Transformer cannot compress the context , longer sequences not only mean a quadratic increase in cost (a 2x increase in sequence means a 4x increase in computational cost, or a 3x increase in the sequence means a 9x increase in computational cost); Exploded due to increase in KV Cache size. In short, running very long sequences is very expensive.
The KV cache is a “cache memory” for the model, avoiding having to recompute large amounts of redundant attention data, which would otherwise be economically unfeasible. Here is an in-depth review of what KV cache is and how it works.
In short, running very long sequences is so expensive that Transformer is not even considered for modalities with extremely long sequence lengths, such as DNA.
In fact, in DNA models like EVO, researchers use the Hyena operator instead of attention to avoid the quadratic relationship mentioned earlier. The Hainer operator uses long convolutions instead of attention to capture long-range dependencies at sub-quadratic cost.
Essentially, while you compute the convolution in the time domain, you compute it as a point-wise product in the frequency domain, which is faster and cheaper. Other alternatives seek a hybrid approach that, rather than abandoning attention entirely, finds the sweet spot between attention and other operators to reduce costs while maintaining performance.
Summarize
Recent examples include Jamba, which cleverly mixes Transformers with other more efficient architectures such as Mamba.
Mamba, Hyena, Attention…you might think I’m just throwing out some fancy words just to prove a point.
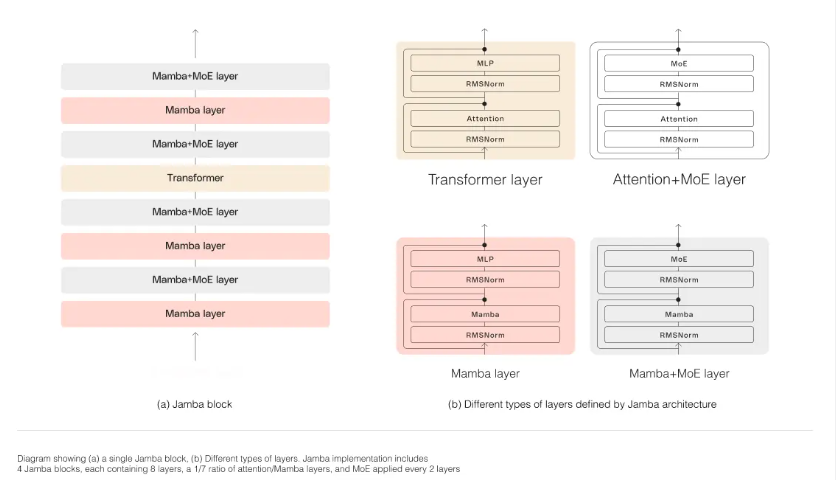
What all these names boil down to is the same principle: they are different ways of revealing language patterns that help our AI models understand text.
Attention mechanisms drive 99% of today’s models, the rest are just trying to find cheaper ways to make large language models (LLMs) more economical with the smallest possible performance degradation.
All in all, we could soon see extremely long sequences being processed at a fraction of current prices, which should raise doubts about the need for RAG architectures.
If RAG can be a good solution to balance costs, then there should be better development in the future.