

It takes three steps to put an elephant in the refrigerator, and the same goes for using whisper to make a voice chat bot.
The overall idea is relatively intuitive, one is recording, the other is transcribing, and the third is chatting:
- Use to
pyaudiomonitor the microphone input, sample every 30 milliseconds, and then store the sampling data of a certain period of time into an audio file; - Call
faster-whisperto transcribe the audio file and obtain the text; - Send text to
ChatGPTGenerate reply. Repeat the above process to achieve a simple voice chat mode.
The project process is shown below:
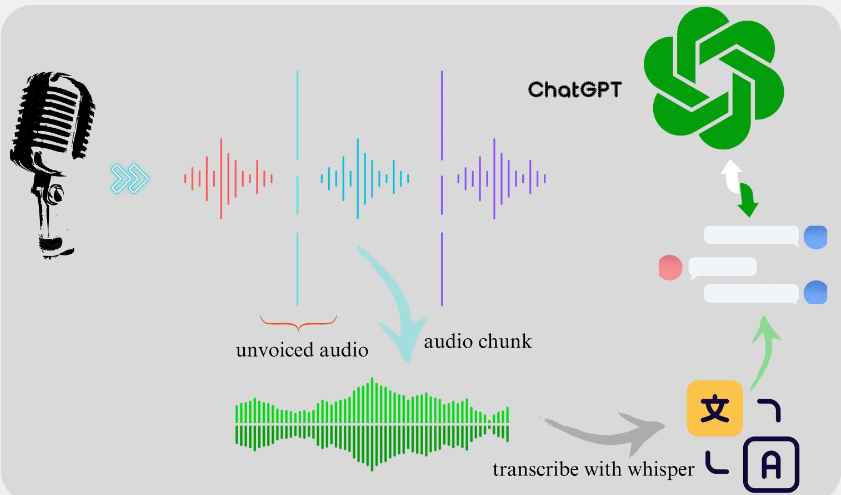
Low latency speech transcription
The underlying model of speech transcription is OpenAI’s open source whisper , and the version with the best effect is large v3. The English word error rate of this version is about 5%, and the Chinese word error rate is about 10%. This level is barely enough. Through actual experience, most cases can be correctly transcribed, but when the pronunciation is not clear enough, recognition errors may occur. For example, “The Romance of the Three Kingdoms” is transliterated into “The Romance of Three Views.”
Whisper’s transcription effect is relatively good among open source models, but its speed is not fast enough. A 13-minute audio session takes about 4m30s using Tesla V100S, and the maximum video memory usage is 13GB. The Faster-whiper model is rewritten using Ctranslate2 based on whisper . The speed is improved by 4 times and the memory usage is also significantly reduced. For example, for the same 13 minutes of audio, faster-whisper’s transcoding time is reduced to about 50s, and the memory usage is also reduced to 4.7GB. Using Kaggle’s T4x2 GPU, the actual test uses faster-whisper to transcribe a speech of about 10 seconds, and the time is about 0.7 seconds. This speed can already meet the needs of (pseudo) real-time transcription.
As mentioned above, the audio is obtained through sampling, but the input of the audio signal is continuous. Whisper can only be transcribed offline and does not support streaming. In order to simulate streaming transcription, the audio signal needs to be converted into short segments of audio and then passed to the whisper.
Two options are considered for audio interception, one is to intercept the audio input according to a fixed duration , and the other is to intercept the entire sentence . The former kind of delay is guaranteed, but the transcription effect is poor; the second kind of transcription effect is good, but the delay is difficult to control. Because this project is not strictly a real-time transcription, whether the delay is 2 seconds or 5 seconds, it will have little impact on the experience. After weighing the transcription effect and delay, we finally chose the second option.
Solution 1: Truncate audio input according to duration
Use to pyaudiomonitor the microphone input and sample every 30 milliseconds. If it is detected that the audio exceeds the preset duration, the audio will be cut off, the wav file will be output, and then faster-whisper will be called for transcription.
The advantage of this solution is that it is simple to implement and the delay can be very low. For example, if it is truncated and transcribed every 0.5 seconds, then theoretically the delay can be as low as 0.5 seconds. Of course, the premise is that the machine performance is good enough, such as a 4090 GPU. In this case, the transfer delay is negligible.
But the disadvantage is also obvious, that is, there are many transcription errors. Because the truncation time point is likely to be in the middle of a sentence, this will lead to a lack of context during audio transcription, and the transcription error rate will be higher. Speaking of which, I happened to see a similar project on YouTube recently. The video owner claimed to have developed an ultra-low-latency speech transcription service. However, I analyzed the video and found that there were obvious missing words in the transcribed results. phenomenon, and there are traces of post-editing. I guess he may have used this method, resulting in unsatisfactory transcription results.
Option 2: Intercept the entire sentence
Borrowing webrtcvadthe monitoring microphone input, when voice input is detected, the recording starts until a continuous silence time is detected, such as 0.5 seconds, then the sentence is considered to be over, the wav file is then output, and then faster-whisper is called to transcribe. .
The advantage of this solution is that it can ensure the integrity of the audio, and the audio obtained is basically a complete sentence. But the disadvantages are:
- High latency : It is complex to implement and will cause a certain delay. Especially when a sentence is long and there is no long pause in the middle, this delay will be more obvious.
- Contextual information is still insufficient : Although the integrity of a sentence can be guaranteed, the contextual information before and after the sentence is still missing, and the transcription effect will still be affected.
The problem of insufficient computing power
Ideally, after obtaining the audio, call faster-whisper immediately to transcribe, and then call ChatGPT to generate a reply. But in fact, recording equipment (such as mobile phones and old laptops) may have limited performance and cannot meet this demand. For example, the 2015 MacBook Pro in my hand, just by running faster-whisper, the CPU reaches 100%, and it also freezes intermittently. We have no choice but to separate the audio recording and transcription services. After recording the audio, synchronize the audio to the transcription module first, and then call faster-whisper.
The transliteration module uses Kaggle’s T4 GPU. When recording, the audio is cut off according to the maximum silence of 0.5 seconds. After the local recording, the audio is first synchronized to the redislabsredis instance. The transliteration module on the Kaggle side pulls the audio from redis and then converts it. Write. In actual use, the delay can be controlled to about 2 seconds in most cases. But sometimes in order to cater to this “silence detection”, you need to pause deliberately after finishing a sentence.
Of course, there are other optimization directions for reducing latency, and they are all methods of exchanging computing power for experience. If the GPU is powerful, you can combine the solution of recording audio with windowing and transcribe immediately after recording. When a long period of silence is monitored, the segment before the silence begins has actually been transcribed, and the corresponding result can be returned directly.
The overall effect of this simulation solution depends on several aspects: first, the audio data acquisition solution, second, the performance of the transcription model, and third, the efficiency of data transmission. The limit of optimization is only to transcribe a sentence as correctly as possible within a few tenths of a second. This is not feasible for professional real-time transcription scenarios, but for some simple scenarios, such as voice chat bots, this solution That’s enough.
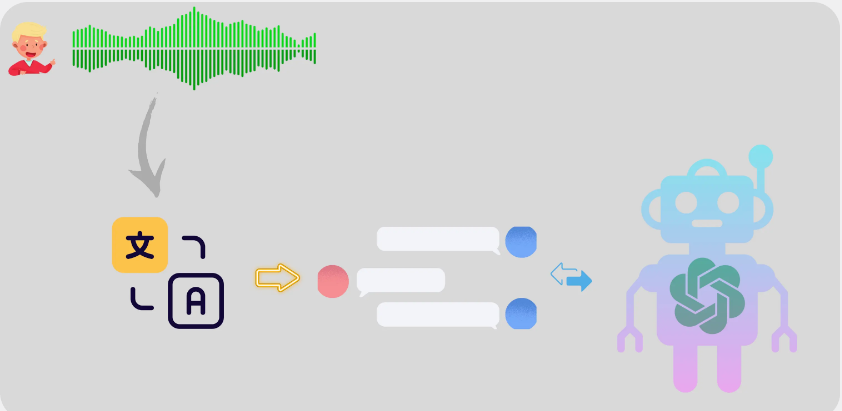
voice chatbot
After getting the text, the rest is simple. Just call the chat bot interface and pass in the text. The intelligence of a Bot depends on the capabilities of the model behind it. Currently, GPT-4 is still the No.1, but the cost is a bit high.
The model used in this project is ChatGPT, which is free and has good results. To convert ChatGPT into a service that supports RESTful API, we refer to pandoranext , a recently popular ChatGPT api wrapper project . This project can proxy the GPT model behind ChatGPT into an API. Unfortunately, due to various reasons, the project author is about to give up subsequent maintenance, and some of the services it relies on will also be shut down at the end of this month.
If the chat service must use an open source model, the English model can be deployed with mixtral 7x8b , and the Chinese model can consider Yi-34B-Chat , which is an open source model . As of 2024/01/29, Yi-34B-Chat ranks 13th on the LMSYS Chatbot Arena Leaderboard and is the best among Chinese models.
Code and related resources
- faster-whisper github page: github.com/SYSTRAN/fas…
- openai/whisper: github.com/openai/whis…
- Code repository: github.com/ultrasev/st…