

Meta Llama development history
Llama 1
Llama is an open source project released by Meta(FaceBook) AI, which allows commercial use and has huge influence. Llama 1 is Meta’s first step into the world of artificial intelligence language models in 2021. It is very smart and is able to understand and create language, thanks to the 7 billion parameters it possesses. But it’s not perfect, and sometimes it has trouble understanding complex ideas, or basic facts aren’t always known.
Llama 2
After learning from Llama 1, Meta launched Llama 2 in 2022. This version is larger, with 21 billion parameters, and made smarter by reading more books, Wikipedia, and public domain content. Llama 2 gets better at figuring things out, understanding what people mean, and knowing more facts. Llama 2 supports 4096 context, has excellent performance, and is considered (one of) the biggest competitors of the GPT series.
Core improvements to Llama 2: Fine-tuned with human alignment, Llama 2 is better at understanding what people mean and can more accurately translate words into actions. It is smarter in logic, learns more facts by reading information from different sources, and knows more common sense. It performed well on tests that detect how well the AI performs on language tasks.
But even with these upgrades, Llama 2 still has a lot of room for growth, especially in terms of handling complex language challenges. There is still a big gap between GPT 3.5 and GPT 4, which also led to the emergence of Llama 3.
Llama 3
At 0:00 on April 19, Meta released the Meta Llama 3 series of language models (LLM), specifically including an 8B model and a 70B model. In the test benchmarks, the Llama 3 model performed very well, and in practicality and security evaluations, it was comparable to those popular closed-source models on the market.
Models are available as open source in 8B and 70B parameter sizes, covering pre-trained and instruction-tuned variants. Llama 3 supports a variety of commercial and research uses and has demonstrated superior performance in multiple industry standard tests.
Llama 3 properties
Benchmark performance
Compared with other large models with large number of parameters, Llama 3 is in the leading position in its category. It is particularly good at thinking about problems, understanding stories, summarizing things, and chatting. In tests, Llama 3 performed better than many other models, scoring higher on a measure of these AI’s language intelligence.
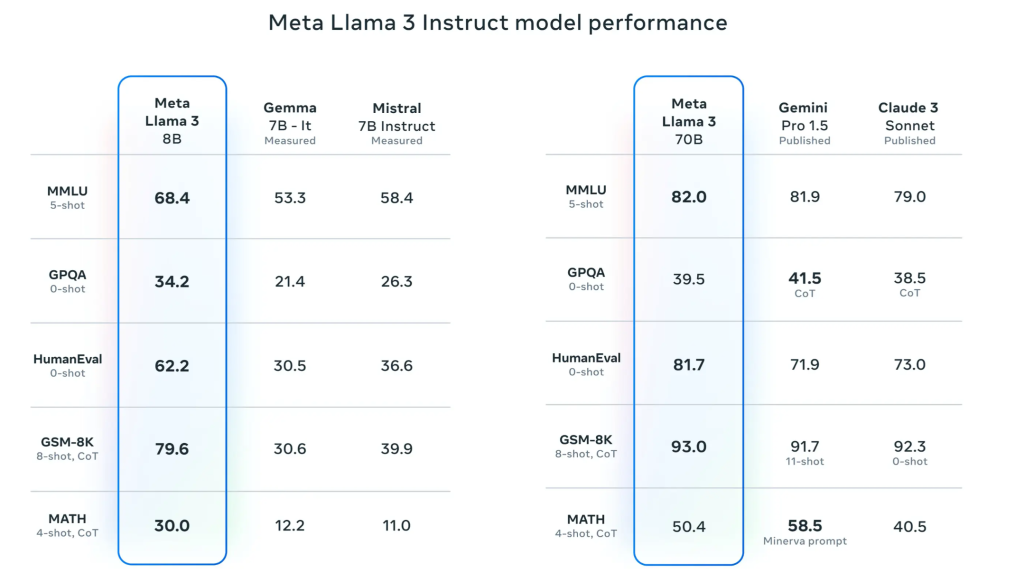
Meta official data shows that the Llama 3 8B model outperforms the Gemma 7B and Mistral 7B Instruct models of the same parameter magnitude on many benchmarks such as MMLU, GPQA, and HumanEval, while the 70B model surpasses the popular closed-source model Claude 3 Sonnet. And the effect is completely comparable to Google’s Gemini Pro 1.5.
instructions to follow
Llama 3 did an excellent job of understanding and following the steps of various tasks. It learns by example and provides a better understanding of what you want it to do, whether that’s cooking, coding, or assembling something. Imagine telling it to make a cake and it would list all the ingredients and baking steps.
It has a success rate of over 90% in accurately executing instructions, which is a huge improvement over earlier versions. This means it is getting closer to understanding complex instructions, just like humans.
This could lead to smart assistants using our words to perform actions we ask for, making everyday tasks easier.
knowledge reasoning
Llama 3 is great at connecting different ideas and giving smart answers. It’s like having a conversation with someone who knows a lot about a lot of things. It can assemble information from different places to answer difficult questions about science or history; figure out why things happen the way they do; make rational guesses about problems; and discover the problem by comparing it with known facts.
It’s as good as some of the best AI at solving puzzles that require logic and knowledge, and it’s getting better and better at understanding complex concepts. Llama 3 is knowledgeable because it has read a lot of information on a variety of topics, which helps it think about problems in areas like economics or language patterns. In the future, because of the way AI learns and understands the world, we may see AI know as much as experts in different fields.
Llama 3 architecture
Pre-training data
In preparation, Llama 3 obtained a large amount of mixed information from more than 30 languages, including books, Wikipedia, news and websites, totaling about 1.5 trillion bits of information. It learns by trying to fill in missing words or parts of text, which makes it very good at understanding language.
Overall, the training data set for Llama 3 is more than seven times larger than the data set used by Llama 2 and contains four times more code. To prepare for upcoming multilingual use cases, over 5% of the Llama 3 pre-training dataset consists of high-quality non-English data spanning over 30 languages.
Training optimization
Training Llama 3 models combines three approaches to parallelization: data parallelism, model parallelism, and pipeline parallelism. The most efficient implementation achieved over 400 TFLOPS of compute utilization per GPU when using 16K GPUs for training simultaneously, with training runs performed on two custom 24K GPU clusters. To maximize GPU uptime, an advanced new training platform was developed that automates error detection, handling, and maintenance. We have also greatly improved hardware reliability and silent data corruption detection mechanisms, and developed a new scalable storage system that reduces checkpointing and rollback overhead. These improvements result in an overall effective training time of over 95%. Taken together, these improvements increase the training efficiency of Llama 3 by about three times compared to Llama 2.
model framework
Meta Llama 3 still uses the optimized autoregressive Transformer architecture, which is specially designed to handle complex text generation tasks and can effectively improve the coherence and relevance of generated text. The model combines supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF). This hybrid method not only enhances the helpfulness of the model, but also improves security, making the model more reliable and in line with user expectations in practical applications. .
Compared with Llama 2, Llama 3 has made several key improvements, including: Llama 3 uses a tokenizer with a 128K token vocabulary, which can encode language more efficiently, thereby significantly improving model performance; in order to improve the performance of the Llama 3 model For reasoning efficiency, the research team adopted group query attention (GQA) on models of 8B and 70B sizes; trained the model on a sequence of 8192 tokens, and used masks to ensure that self-attention does not cross document boundaries.

Conclusion
Meta’s Llama 3 model not only advances the cutting-edge of AI technology, but also promotes the innovation and ethical development of advanced language models on a global scale through free and open access. As Llama 3 continues to be optimized, we look forward to its further development in multi-modal capabilities, multi-language support, and domain-specific knowledge. Meta encourages developers and researchers to incorporate the power of Llama 3 into their work in a safe and responsible way by providing easy-to-use models, cloud options, setup tools, and rich learning resources. This is not only a leap forward for Meta in the field of AI, but also heralds a more intelligent and connected future.