

1 Introduction
The exploration of Scaling Law in the field of deep learning has led to the rapid improvement of the performance of existing large language models (LLM). This article explores another area for improvement: the quality of the data. Eldan and Li’s recent work on TinyStories (a high-quality synthetic dataset used to teach neural networks English) shows that high-quality data can significantly change the shape of the scaling law, potentially allowing for leaner training/models. Achieve large-scale model performance . This paper shows that high-quality data can improve even the state-of-the-art on large language models (LLMs) while drastically reducing dataset size and training computation. Importantly, smaller models that require less training can significantly reduce the cost of LLMs.
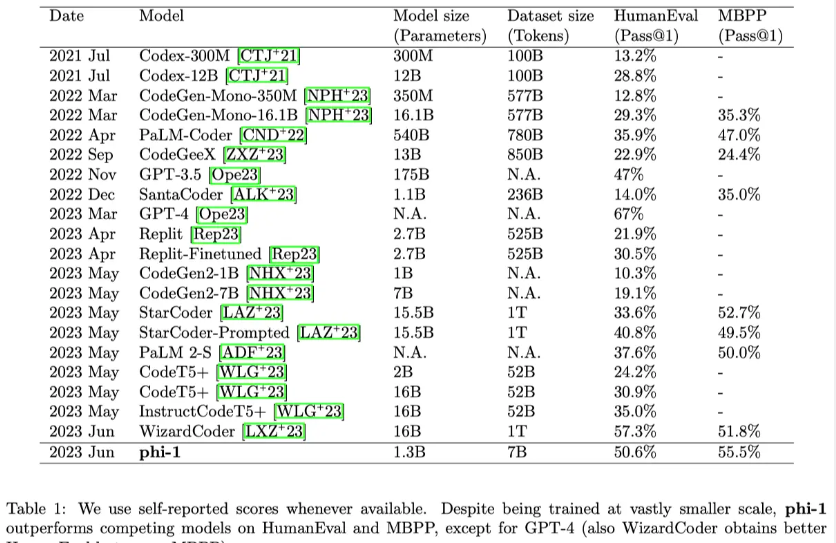
This article focuses on code-trained LLMs (Code LLMs), that is, writing simple Python functions from docstrings, by training a model containing 1.3 billion parameters (called phi-1), which takes about 8 iterations. Each time, 7B tokens (tokens, about 50B tokens in total) were processed, and then less than 200M tokens were fine-tuned to demonstrate the power of high-quality data in breaking the existing scaling laws. Roughly speaking, this paper pre-trains on “textbook quality” data, including synthetically generated data (using GPT-3.5) and filtered data from web sources, and fine-tunes on “textbook exercise-like” data. Despite being orders of magnitude smaller than competing models in terms of dataset and model size (Table 1), it achieved 50.6% Pass@1 accuracy on HumanEval and 55.5% Pass@1 accuracy on MBPP Rate.
The article is organized as follows: Section 2 provides some details of the training process and discusses the evidence for the importance of the data selection process in achieving this result. Furthermore, although phi-1 is trained on a much smaller number of tokens than existing models, it still shows emergent properties. These emergent capabilities are discussed in Section 3, and in particular by comparing the output of phi-1 with the output of phi-1-small (a model using the same pipeline but with only 350M parameters), the authors confirm that the number of parameters plays a role in emergent to a key role. In Section 4, alternative benchmarks for evaluating the model are discussed. Section 5 studies possible contamination of training data with HumanEval.
2. Training details and the importance of high-quality data
The core elements of this article rely on textbook-quality training data. This differs from previous work using standard text data for code generation, such as The Stack (which contains warehouse source code and other web-based datasets such as StackOverflow and CodeContest). This article believes that these sources are not the best options and cannot effectively teach the model how to perform algorithmic reasoning and planning. On the other hand, the model architecture and training methods of this article are quite conventional (see Section 2.3), so this section mainly explains how this article curates the data.
Many snippets in standard code datasets are not suitable for learning the basics of coding and suffer from several shortcomings:
- Many samples are not self-contained, they depend on other modules or files that are external to the fragment, making them difficult to understand without additional context.
- Typical examples do not involve any meaningful calculations, but consist of trivial or boilerplate code such as defining constants, setting parameters, or configuring GUI elements.
- Examples containing algorithmic logic are often buried inside complex or poorly documented functions, making them difficult to understand or learn.
- These examples are biased towards certain topics or use cases, resulting in an uneven distribution of coding concepts and skills in the dataset.
It would be inefficient for a human learner to attempt to acquire coding skills from these datasets because of the large amount of noise, ambiguity, and incompleteness that must be dealt with in the data. The authors hypothesize that these issues also impact language model performance because they reduce the quality and quantity of signals that map natural language to code. Therefore, the authors speculate that language models would benefit from a training set that has the same characteristics as a good “textbook”: it should be clear, self-contained, pedagogical, and balanced. This paper shows that by intentionally selecting and generating high-quality data, state-of-the-art results on code generation tasks can be achieved with smaller models and less computation than existing methods. The training of this article relies on three main data sets:
- D1. Filtered code language dataset, which is a subset of The Stack and StackOverflow, obtained by using a language model-based classifier (containing ~6B tokens).
- D2. A synthetic textbook dataset consisting of less than 1B tokens of Python textbooks generated by GPT-3.5.
- D3. A small synthetic exercise dataset consisting of approximately 180M tokens of Python exercises and solutions.
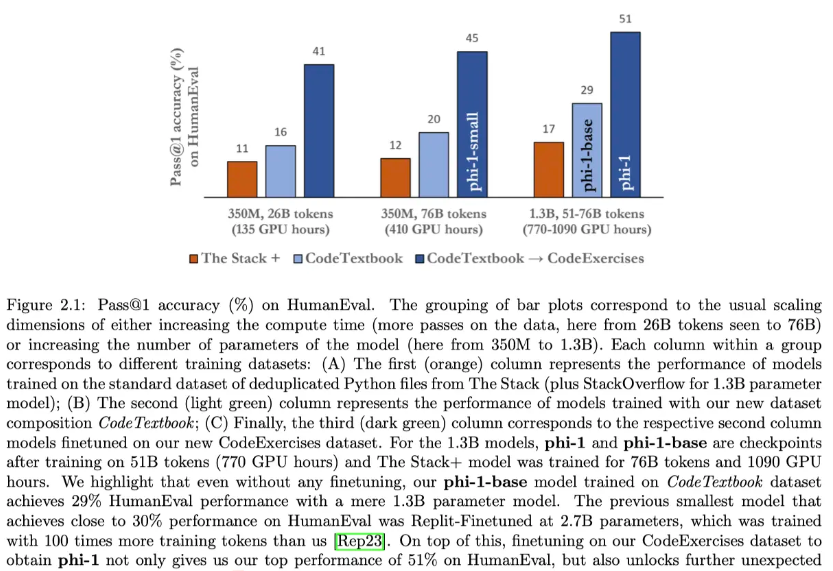
The above data set contains less than 7B tokens in total. This article calls the combination of D1 and D2 “CodeTextbook” and uses it in the pre-training stage to obtain the basic model phi-1-base. Then, the phi-1-base model is fine-tuned to obtain phi-1 using the synthetic exercise dataset D3, called “CodeExercises”. Despite the small size of the “CodeExercises” dataset, fine-tuning using this dataset was critical to generating large improvements in simple Python functions, as shown in Figure 2.1, and more broadly, fine-tuning can also unlock phi-1 There are many interesting emergent capabilities in the model that are not observed in phi-1-base (see Section 3).

2.1 Filter existing code datasets using Transformer-based classifiers
This article uses a Python subset of the deduplicated version of The Stack and StackOverflow, which contains more than 35 million files/samples and more than 35B tokens. A small subset of these files (~100,000 samples) were quality-annotated using GPT-4: given a code snippet, the model was prompted to “determine its educational value to a student whose goal is to learn basic coding concepts.” This annotated dataset is then used to train a random forest classifier that predicts the quality of files/samples using the output embeddings of the pre-trained code generation model as features.
2.2 Creating synthetic textbook-quality datasets
Ensuring that examples are diverse and non-repetitive is a major challenge when creating high-quality datasets for code generation. Diversity includes a wide range of coding concepts, skills, and scenarios, as well as variations in difficulty, complexity, and style. Inspired by previous work, a diverse set of ization’s short story, this article explores methods of injecting randomness into cues, aiming to provide diversity by injecting randomness and constraints to help models learn and generalize better. In order to achieve diversity, this paper designs two synthetic datasets: the synthetic textbook dataset and the CodeExercises dataset.
Synthetic textbook dataset
This dataset contains just under 1B Python textbook tokens generated by GPT-3.5, synthesized to provide a high-quality source of natural language text intertwined with relevant code snippets. Here is an example text from a synthetic textbook:

CodeExercises dataset
This is a small synthetic exercise dataset consisting of less than 180M Python exercise and solution tokens. Each exercise is a docstring for a function that needs to be completed. The goal of this dataset is to align model execution functions to complete tasks through natural language descriptions. The following fragment illustrates an exercise in synthetic generation:

2.3 Model architecture and training
This article uses the multi-head attention (MHA) decoder Transformer model implemented by FlashAttention, and also adopts a structure in which the MHA and MLP layers are configured in parallel. The architecture of the phi-1 model with 1.3B parameters includes 24 layers, a hidden dimension of 2048, an MLP internal dimension of 8192, and 32 attention heads with a dimension of 64. The smaller phi1-small model with 350M parameters includes 20 layers, a hidden dimension of 1024, an MLP internal dimension of 4096, and 16 attention heads with a dimension of 64. Use rotated position embedding with rotation dimension 32. Uses the same tokenizer as codegen-350M-mono.
For pretraining and fine-tuning, concatenate the respective datasets into a single 1D array, using the “⟨∣endoftext∣ ” tag to separate the files. Slice sequences of length 2048 from the dataset array and train using next token prediction loss.
pre-training
phi-1-base was trained on the CodeTextbook dataset (filtered code language corpus and synthetic textbooks). Batch size 1024 (including data parallelism and gradient accumulation), maximum learning rate 1e-3, warmup of 750 steps, weight decay 0.1, and a total of 36,000 training steps. Use the checkpoint at step 24,000 as phi-1-base.
fine-tuning
phi-1 is obtained by fine-tuning phi-1-base on the CodeExercises dataset. For fine-tuning, use the same settings as pre-training, but different hyperparameters: use an effective batch size of 256, a maximum learning rate of 1e-4, a warmup of 50 steps, and weight decay of 0.01. A total of 6,000 steps were trained and the best checkpoints were selected (one checkpoint was saved every 1000 steps).
3. Sudden increase in model capabilities after fine-tuning
As shown in Figure 2.1, fine-tuning on the small CodeExercises dataset resulted in the largest improvements in HumanEval. Presented in this section is the surprising finding that the fine-tuned model also shows significant improvements in performing tasks not demonstrated in the fine-tuned dataset. This includes handling complex algorithmic tasks and using external libraries. This suggests that the fine-tuning process may have helped the model reorganize and consolidate the knowledge acquired during pre-training, even if this knowledge does not exist in the CodeExercises dataset. This section will focus on quantitatively comparing and contrasting the capabilities of the fine-tuned model phi-1 and its pre-trained 1.3B parameter base model phi-1-base.
3.1 Fine-tuning improves the understanding of the model
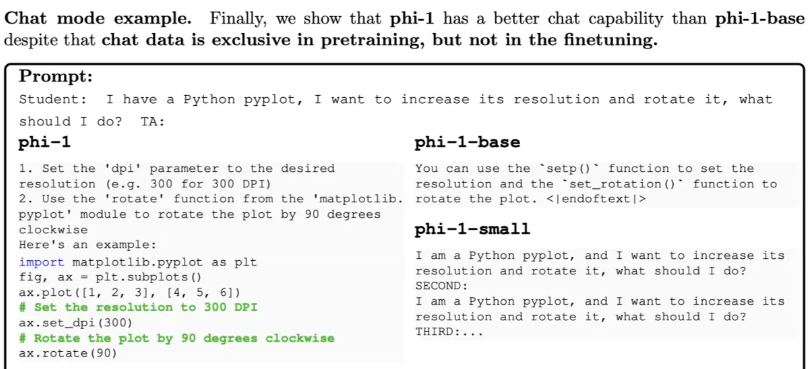
After fine-tuning, the model showed a higher level of understanding and following instructions. The authors found that phi-1-base had difficulty with logical relationships in prompts, whereas phi-1 was able to correctly interpret the questions and generate answers. In this example, even though the 350M phi-1-small model shows a certain level of problem understanding, the generated solution is still wrong.

3.2 Fine-tuning improves the model’s ability to use external libraries
Here are 3 examples. Although the fine-tuning dataset does not contain external libraries such as Pygame and Tkinter, fine-tuning on CodeExercises unexpectedly improved the model’s ability to use external libraries. This shows that fine-tuning not only improves the targeted task, but also makes unrelated tasks easier to extract from pre-training. For reference, Figure 3.1 shows the import distribution of packages in the CodeExercises dataset.

Completion of the three models revealed huge gaps in their understanding of prompts. Both phi-1-base and phi-1-small failed to use the correct Tkinter API and made meaningless function calls. On the other hand, phi-1 implements the GUI and all functions correctly (except “pewpewpew?” which is not copied correctly).
4 Assessment of non-routine problems using LLM scoring
There may be a potential problem with the surprisingly good performance of phi-1 on HumanEval (see Table 1 and Figure 2.1), that is, the synthetic CodeExercises dataset may have caused a memory effect. Section 5 directly studies this potential contamination, while this section develops a new evaluation dataset. These problems were created by a dedicated team without access to the CodeExercises dataset or final model. They created 50 new questions in the same format as HumanEval, with instructions to design questions that were unlikely to appear in an actual codebase or coding exercise. Here is an example of such a question:

One challenge with evaluating language models on coding tasks is that the output of the model is often binary: either the code passes all unit tests, or it fails. However, this does not capture the subtleties of the model’s performance, as it may produce code that is almost correct but has minor errors, or a code that is completely wrong but coincidentally passes some tests. Arguably, a more informative way of assessing a model’s coding skills is to compare its output to the correct solution and score it based on how well it matches the intended logic. This is similar to how humans are evaluated in coding interviews, where the interviewer not only runs the code but also checks the reasoning and quality of the solution.
Therefore, in order to evaluate candidate solutions, this paper adopts the method of using GPT-4 to score solutions. This approach has two clear advantages: (1) by using GPT-4 as a scorer, its knowledge and generative capabilities can be leveraged to obtain a more refined and meaningful signal of the student model’s coding ability, and (2) it Eliminates the need for testing. The prompt instructs the LLM to first give a brief verbal evaluation of the student’s solution and then assign a grade from 0 to 10.
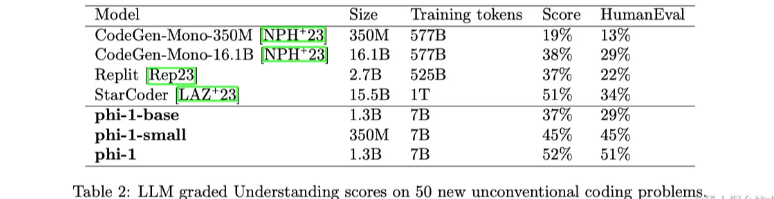
Table 2 shows the results for phi-1 and competing models. The results on new non-routine problems are the same as HumanEval (see Table 1). phi-1 again achieves significantly higher scores than StarCoder, just like on HumanEval. Considering that new questions have no chance of contaminating the training data and, more importantly, they are designed to be outside the training distribution, these results greatly enhance confidence in the effectiveness of phi-1 performance.
5 Data pruning for unbiased performance evaluation
As can be seen in Figure 2.1, training on CodeExercises significantly improves the model’s performance on the HumanEval benchmark. To investigate this improvement, the authors trimmed the CodeExercises dataset by removing files that were “similar” to those in HumanEval. This process can be viewed as a “strong form” of data decontamination. The phi-1 model was then retrained on such pruned data and strong performance on HumanEval was still observed. In particular, retrained phi-1 still outperforms StarCoder even after aggressively pruning more than 40% of the CodeExercises dataset (this even prunes files that are only slightly similar to HumanEval, see Appendix C).
The authors believe that this data pruning experiment is a fair way to evaluate performance and is more insightful than the standard “contamination” studies typically found in the literature based on overlap measures between training and test data. For the sake of completeness, the author first conducted a standard contamination experiment, and the results showed that CodeExercises was not contaminated by HumanEval in this standard sense.
5.1 N-gram overlap
The N-gram metric measures the similarity of text segments based on shared sequences of n words. N-gram overlap analysis shows that there is almost no letter-level overlap between our dataset and HumanEval.

5.2 Embedding and grammar-based similarity analysis
The authors also use a combination of embeddings and syntax-based distance. Embeddings are derived from the pretrained CodeGen-Mono 350M model, and the L2 distance between embeddings of code snippets is calculated. The authors observed that embedding distance successfully captured code pairs whose overall code semantics were similar. For syntax-based distance, the authors calculated the (string) edit distance between the abstract syntax trees (ASTs) of two given code snippets. AST distance successfully identifies overlaps between code pairs while remaining agnostic to non-grammatical text such as variable/function naming, comments, and Python Docstrings. For CodeExercises pruning, the authors fixed the threshold of embedding distance and tested the matching rate τ of several AST distances. Varying τ from 0.95 to 0.8, this corresponds to removing 42.5K to 354K of CodeExercises’ 879.5K total problems.
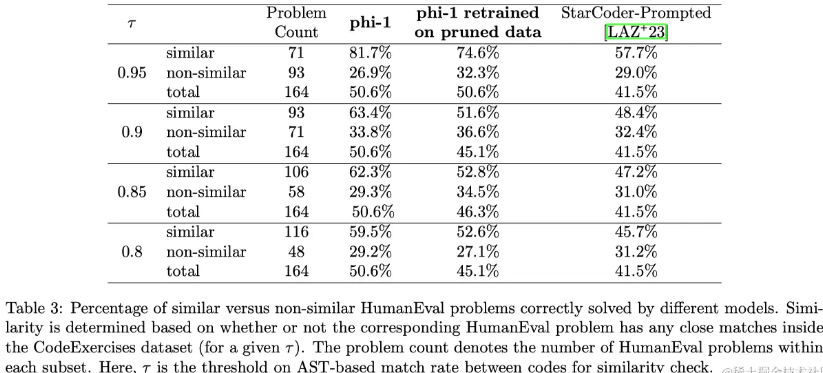
Table 3 summarizes the performance of retrained phi-1 on the pruned dataset. Divide the HumanEval problem into two subsets (“similar” and “non-similar”), based on whether they have at least one close match (for a given τ) in the original CodeExercises dataset, and report the model’s performance on each HumanEval subset separately on the accuracy rate. It can be seen that even after pruning the dataset significantly, phi-1 still significantly outperforms StarCoder-Prompted, which verifies that the performance improvement is not due to “contamination” of the dataset, even if the latter term has a broad meaning.
6 Summary
This study shows that high-quality data is critical to the performance of language models in code generation tasks. By creating “textbook quality” data, the trained models are far ahead of other open source models such as HumanEval and MBPP in both model size and dataset size. The authors believe that high-quality data can greatly improve the efficiency of language models learning code because they provide coding examples that are clear, self-contained, educational, and balanced. Although the phi-1 model still has some limitations, such as its exclusive use for Python coding, lack of domain-specific knowledge, and lower tolerance for style changes, these limitations are not insurmountable. More work could address these limitations and improve model performance.
