

I’ve looked at regex and JSON persistence generated using LLM , but many believe that AI handles Structured Query Language (SQL) well . To celebrate SQL’s 50th birthday , let’s discuss tables, introducing technical terminology where necessary. However, I don’t want to just test the query against an existing table . The world of relational databases begins with Schema .
A Schema describes a set of tables that interact to allow SQL queries to answer questions about a model of a real-world system. We use various constraints to control how tables relate to each other. In this example, I will develop a schema for books, authors, and publishers. We will then see if LLM can replicate this work.
We start with the relationships between our things . A book is written by an author and published by a publisher. In fact, the publication of a book defines the relationship between author and publisher.
So, specifically, we want to produce the following results:
| Book | Author | Publisher | Release Date |
|---|---|---|---|
| The Wasp Factory | Iain Banks | Abacus | February 16, 1984 |
| Consider Phlebas | Iain M. Banks | Orbit | April 14, 1988 |
This is nice to read (we’ll come back to it later), but the table itself is not a good way to maintain more information.
If the publisher’s name was just a string, you might need to enter it multiple times—which is both inefficient and error-prone. So does the author. Those of you with a literary bent will know that the author of both books (Iain Banks) is the same person, but he used slightly different pseudonyms when writing science fiction.
What happens if the book is later re-released by a different publisher? To ensure that these two publishing events are distinguished, we need to provide both the book title and the release date – so our primary key or unique identifier must include both. We want the system to reject two books with the same title and publication date.
Instead of using one big table, we use three tables and reference them when needed. One for the author, one for the publisher, and one for the book. We write the authors’ details in the Authors table and then reference them in the Books table using foreign keys .
So, the following is a Schema table written using Data Definition Language ( DDL ). I’m using a MySQL variant – annoyingly, all vendors still maintain slightly different dialects.
First, there is the author table. We add an automatic ID column index as the primary key. We haven’t actually solved the pseudonym issue (I leave that to the reader):
CREATE TABLE Authors (
ID int NOT NULL AUTO_INCREMENT,
Name varchar(255) not null,
Birthday date not null,
PRIMARY KEY (ID)
);
The publisher table follows the same pattern. “NOT NULL” is another constraint that prevents data from being added without content.
CREATE TABLE Publishers (
ID int NOT NULL AUTO_INCREMENT,
Name varchar(255) not null,
Address varchar(255) not null,
PRIMARY KEY (ID)
);
The books table will reference a foreign key, which makes it logical but a bit difficult to understand. Note that we respect that the title of the book and its publication date together form the primary key.
CREATE TABLE Books (
Name varchar(255) NOT NULL,
AuthorID int, PublisherID int,
PublishedDate date NOT NULL,
PRIMARY KEY (Name, PublishedDate),
FOREIGN KEY (AuthorID) REFERENCES Authors(ID),
FOREIGN KEY (PublisherID) REFERENCES Publishers(ID)
);
To see a neat table at the top, we need a view . This is just a way of stitching the tables together so that we can pick out the information we need to display while keeping the Schema intact. Now that we have the Schema written down, we can build our view:
CREATE VIEW ViewableBooks AS
SELECT Books.Name 'Book', Authors.Name 'Author', Publishers.Name 'Publisher', Books.PublishedDate 'Date'
FROM Books, Publishers, Authors
WHERE Books.AuthorID = Authors.ID
AND Books.PublisherID = Publishers.ID;
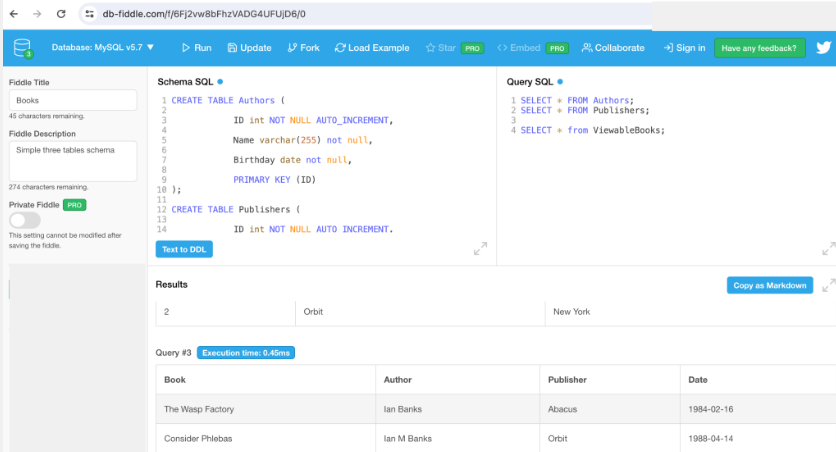
Let’s see if we can generate our Schema in an online playground so that we don’t have to install a database.
DB Fiddle should do the job.
If you enter DDL and then add the actual data:
INSERT INTO Authors (Name, Birthday)
VALUES ('Iain Banks', '1954-02-16');
INSERT INTO Authors (Name, Birthday)
VALUES ('Iain M Banks', '1954-02-16');
INSERT INTO Publishers (Name, Address)
VALUES ('Abacus', 'London');
INSERT INTO Publishers (Name, Address)
VALUES ('Orbit', 'New York');
The result of viewing the view shows up as “Query 3” in the DB Fiddle, which is exactly the data we wanted to see:
Can LLM also create patterns?
Okay, now we want to ask LLM about creating the schema. To summarize how we hope to guide LLM:
- When asking the schema in English, we want it to generate DDL for the three tables, including indexes and constraints.
- We can also imply the need for constraints (primary keys, foreign keys, etc.) if needed.
- We can ask to see it.
- We can direct it to use MySQL syntax if needed.
I’ll be using Llama 3 , but I also looked at OpenAI’s LLM and got roughly the same results.
Our first query: “Create a relational database schema to describe books, publishers, and authors.”
result:
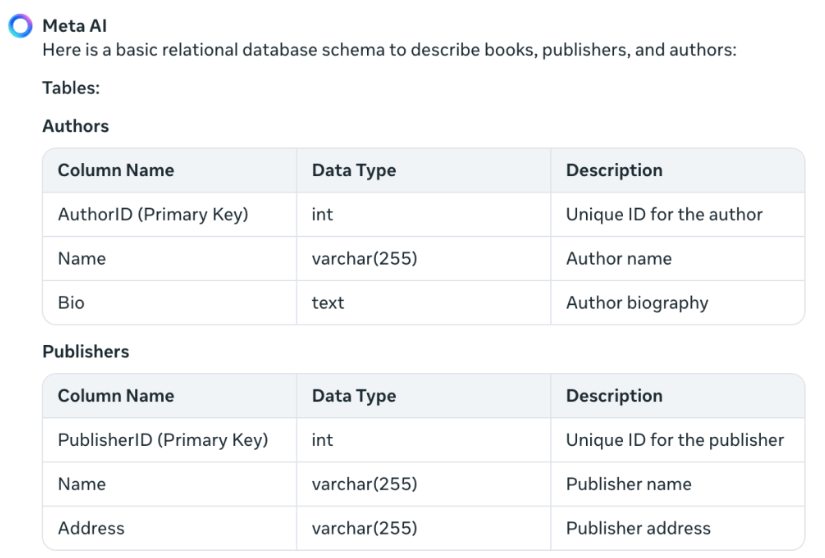
So far so good. It hasn’t created the DDL yet, but we can ask separately. It somehow does a better job of describing the pattern in English. Let’s look at the rest of the reply:
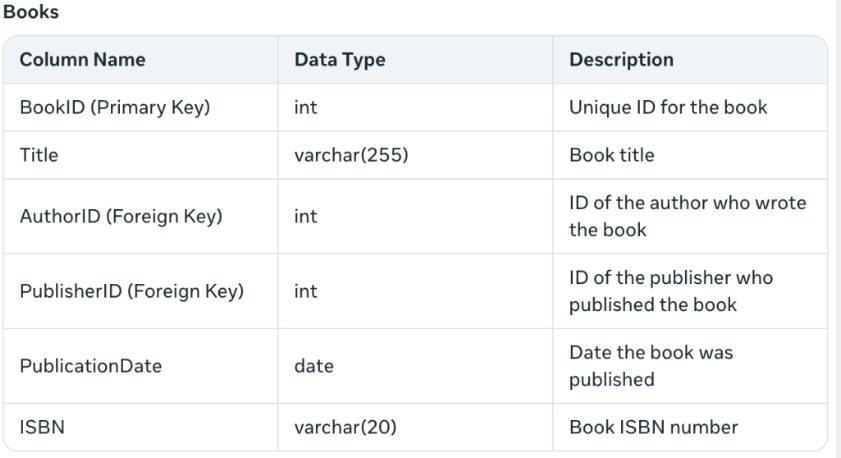
It describes the foreign key constraints and adds the ISBN, which I didn’t expect. Also, “PublicationDate” is more idiomatic than my “PublishedDate”. It also creates a table:
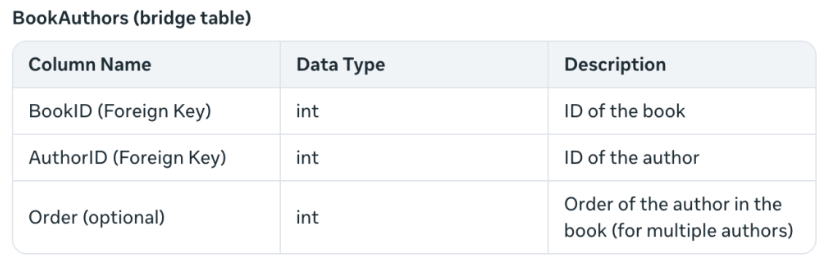
This solves the problem of creating multiple authors for a book – something I hadn’t considered before. The term bridge table indicates that two tables (books and authors) are joined by a foreign key.
Let’s ask DDL: “Show me the data definition language for this schema.”
These are returned correctly, including NOT NULLs, to ensure there are no empty entries. It also states that the DDL is “universal” in some respects due to real-world differences between vendor SQLs.
Finally, let’s ask a view:

This is more complicated than my version; however, it works fine in DB Fiddle when I adjust to my schema naming. The table alias naming seen here is not helpful for understanding.
Conclusion: LLM can indeed create patterns
I think this is a huge win for LLM because they turned my English description into a well-constrained pattern and then into executable DDL, while also providing explanations (although those explanations became for more technical relationship details). I didn’t even use a dedicated LLM or service, so it worked out great.
In a way, this is a mapping of one domain (the publishing world) to another (the domain-specific language of SQL), and it’s very much to LLM’s advantage. Each area is well defined and rich in detail.