
Artificial Intelligence Review and Prospects
Artificial intelligence (AI) is developing at a pace that is difficult to keep up with.
- Ten years ago, the focus was on big data and machine learning (ML). Deep learning has become a new popular concept. The word “AI” is also considered to be a fantasy describing the level of human intelligence in the future. At the time, the technology was primarily used by large technology companies in key areas such as ad optimization, search engines, social media rankings, shopping recommendations and online abuse prevention.
- Five years ago, ML Ops took off, with companies working hard on feature engineering and model deployment. They mainly focus on standard machine learning tasks such as data annotation, churn prediction, content recommendation, image classification, sentiment analysis and natural language processing.
- About a year ago, large language models (LLMs) and basic models revolutionized our expectations of AI. Companies are turning to chatbots, knowledge base-based RAG technology, automated customer support and medical records. Looking forward to 2024 and even further into the future, it seems that intelligent agents and assistive systems are becoming the protagonists, and solving the hallucination problem of LLMs and improving their credibility and practicality in user-oriented products will become the focus. As for what AI will become after that, or even by 2030, obviously no one knows.
However, in this era of rapid innovation, almost all AI-based solutions rely on some stable infrastructure components.
Things that don’t change…

Although there are various artificial intelligence product architectures, it seems that all architectures rely on several core basic components, including model training and hosting, pre-trained basic models, vector databases, model pipelines and data processing, annotation, evaluation frameworks and AI application hosting wait.
These components are nothing new. For example, Google conducts vector search in advertising services, and Meta began building a distributed neural network training system for information flow ranking more than ten years ago. Meanwhile, Amazon generates multimodal embeddings for shopping recommendations, while Microsoft introduces vector-based search and ranking mechanisms for Bing. These are just some of the many cases.
The challenge for other companies in the market is that these AI technology stacks are far under the dominance of large technology companies, which alone have the scale to develop these technologies and the talent to support their development. Other companies need to make a difficult choice between building their own efforts or giving up. Companies like Uber, Netflix, Yahoo, Salesforce, and Pinterest, given the scale of their businesses, are very serious and forward-looking in investing in AI talent and technology.
Now, companies no longer need to struggle with this. They can choose to use AI infrastructure services. In fact, these tools are now mature, easy to use, and affordable. But that’s only part of the story…
future challenges
Before we introduce the emerging technology stack, let’s take a look at the current and future challenges that AI applications will face. It should be pointed out that AI applications have some unique challenges that all software services need to face. The following challenges only involve new and different problems.
Multimodal data and models will soon become the norm. Currently text-based applications will incorporate images and videos. The original service will become more focused on data processing and will need to be re-planned on various interfaces throughout the system.
Data is becoming increasingly large and complex. Huge text and multi-modal data need to be processed by the model and can be immediately accessed by AI applications. Such applications hope to gain knowledge through the inherent meaning of data. However, traditional databases are often helpless when facing this application scenario.
Hardware facilities are undergoing changes. The emerging ecosystem of hardware accelerators will begin to relieve today’s computing shortages, but it will also bring new challenges, such as how to optimize the use of a growing and changing accelerator collection, and how to keep the work portable and performance optimized.
Application development is increasingly AI-centric, tightly integrated with advanced tools and AI capabilities, which means traditional web development is becoming increasingly demanding on storage and computing resources.
Model training is also changing. With the emergence of base models, we no longer simply develop models from scratch. There is now more of a need to retrain and fine-tune models. While this significantly reduces computational requirements, it also introduces new challenges in model customization and composition, which will increase the burden on our model evaluation capabilities.
Cloud computing centers are becoming critical. Because of the trade-off between handling data gravity and model gravity, new cloud-native services are needed. These services need to be able to dynamically optimize compute, storage and network usage. In addition, as cloud portability and inter-cloud interoperability become more and more important, these are usually only major cloud service providers that can provide cloud-native services for the entire AI technology stack.
It goes without saying that for most companies, building these capabilities in-house is both impractical and mostly unnecessary. To seize these new opportunities, companies need to learn how to use the right infrastructure. These infrastructures must not only meet current needs but also meet future challenges. That is, they should be flexible, iterate quickly, and be universally applicable.
Artificial Intelligence Technology Stack
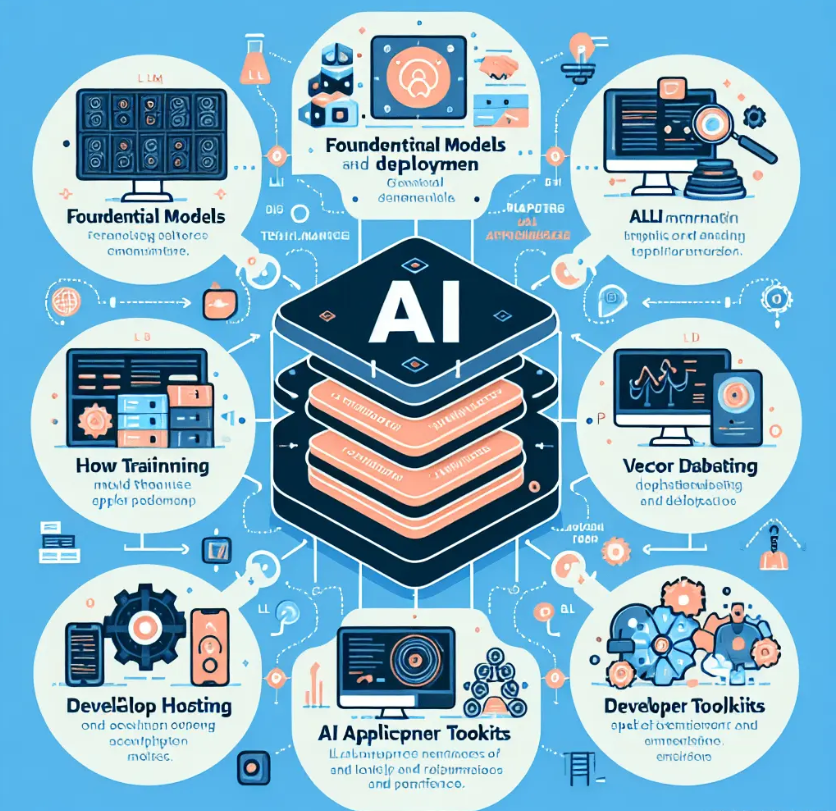
**Base Model:** We expect the model to be able to transform a document or perform a task. Transformation usually means generating vector embeddings or features generated when completing a task. Tasks include text and image generation, annotation, summarization, transcription, etc. Training such a model and running it efficiently in production is challenging and expensive. Companies like AI21 Labs offer industry-leading large-scale language models optimized for embedding and generation tasks, and have also developed highly specialized models for specific business challenges. Not only are these models hosted, they are continuously trained and improved.
**Model training and deployment: **The nature of AI work is computationally intensive. Therefore, successful AI teams need to consider how to scale. They need to scale because the models are larger, the amount of data is larger, and more and more models need to be built and deployed. Just to support the embedded computation of a basic application like RAG, hundreds of GPUs may be required to run for days.
The demand for scale presents a series of software engineering challenges, including performance, cost, and reliability, but none of these can affect the speed of development. Anyscale is developing Ray , an open source project to support industry-wide AI infrastructure to train some of the world’s largest models, such as GPT-4.
**Vector database:** Knowledge is the center of AI, and semantic retrieval is a key means to ensure that the model can obtain relevant information in real time. To do this, vector databases have become sophisticated and specialized, capable of searching billions of embeddings in milliseconds while maintaining cost efficiency. Pinecone recently released its newly built cloud-native serverless vector database, which allows enterprises to scale infinitely and build high-performance applications like RAG faster than ever before. Many companies have reduced database expenses by up to 50 times with this new product.
**AI Application Hosting: **AI applications present some unique new challenges that impact the rendering, delivery, and security architecture of the application. First of all, unlike traditional websites, AI applications are naturally more dynamic, which means that traditional CDN caching is not efficient enough, and applications need to rely on server rendering and streaming to meet users’ needs for speed and customization. Considering the rapid evolution of the AI field, products must be able to iterate quickly, whether it is new models, tips, experiments, or technologies, while application traffic may grow exponentially, making serverless platforms very attractive. In terms of security, AI applications have become popular targets for bot attacks that attempt to steal or deny LLM resources or crawl proprietary data. Next.js and Vercel are actively investing in infrastructure products for GenAI companies that champion the rapid and secure delivery of content to end users.
**LLM Developer Toolkit:** In order to build LLM applications, all the above components need to be integrated to build the “cognitive structure” of the system. Having an LLM toolkit like LangChain can help engineers build applications more quickly and efficiently. Important components of this toolkit include the ability to flexibly create custom chains, diverse integration options, and best-in-class streaming support—all important user experience factors for LLM applications.
**LLM Operations:** Building a prototype is tricky enough, but putting it into production is another level of difficulty. In addition to the hosted applications mentioned above, there are a range of issues related to application reliability that need to be addressed. Common issues include: the ability to test and evaluate different cues or models, tracking and debugging individual calls in the system that may cause problems, and ongoing feedback monitoring over time. LangSmith — built by the LangChain team but framework-agnostic — provides a one-stop solution to these problems.