A pure function is a mathematical ideal state in which the same input always produces the same output without any observable side effects.
Mathematically the function is defined as
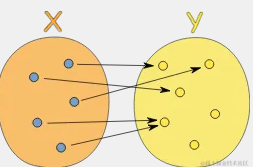
It must work for every possible input value
And it has only one relationship for each input value
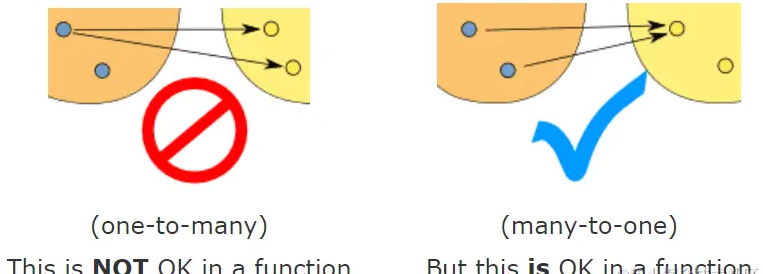
That is, each input within the value range can get a unique output, and it can only be a many-to-one relationship instead of a one-to-many relationship:
side effect
Wikipedia Side Effect : In computer science , an operation, function or expression is said to have a side effect if it modifies some state variable value(s) outside its local environment, which is to say if it has any observable effect other than its primary effect of returning a value to the invoker of the operation. Example side effects include modifying a non-local variable , modifying a static local variable , modifying a mutable argument passed by reference , performing I/O or calling other functions with side-effects. In the presence of side effects, a program’s behavior may depend on history; that is, the order of evaluation matters. Understanding and debugging a function with side effects requires knowledge about the context and its possible histories.
There are many forms of side effects. All behaviors that affect the external state or depend on the external state can be called side effects. Side effects are necessary because programs inevitably interact with the outside world, such as:
Change external files, database reading and writing, user UI interaction, access other functions with side effects, modify external variables
These can be regarded as side effects, and in functional programming we often want to minimize side effects and avoid side effects as much as possible. The corresponding pure function hopes to completely eliminate side effects, because side effects make pure functions impure, as long as A function also needs to rely on external state, so the function cannot always maintain the same input and get the same output.
What are the benefits?
You wanted a banana but what you got was a gorilla holding the banana and the entire jungle . — Joe Armstrong, creator of Erlang progamming
Cacheability , since a unique input represents a unique output, this means that we can directly return the result of the operation without changing the input.
Highly parallel . Since pure functions do not rely on external states, even if the external environment changes in multi-threaded situations, pure functions can always return the expected value. Pure functions can achieve true lock-free programming and a high degree of concurrency.
Highly testable , no need to rely on external state. For traditional OOP testing, we need to simulate a real environment, such as simulating Application in Android and asserting state changes after execution. Pure functions only need to simulate input and assert input, which is so simple and elegant.
Dependencies are clear . Object-oriented programming always requires you to initialize the entire environment, and then the function relies on these states to modify the state. Functions are often accompanied by a large number of external implicit dependencies, while pure functions only rely on input parameters, nothing more, and only provide return value.
Go further
Traditional university teachers teach OOP, so most people will not learn the idea of pure functions at first, but pure functions are a completely different set of programming ideas. The following is an example of implementing a loop in a pure function. Traditional The loop often looks like this:
int sum(int[] array) {
int sum = 0;
for (int i = 0; i < array.length; i++) {
sum += array[i];
}
return sum;
}
Although most languages also provide syntax such as for…in, such as kotlin:
funsum(array: IntArray): Int {
var sum = 0
for (i in array) {
sum += i
}
return sum
}
But we noticed that in the above examples, two variable variables, sum and i, were introduced. From the perspective of sum += i, its external dependence: i is an external variable state, so this function Not “pure”.
But on the other hand, from the external perspective of the overall function, it is still very “pure”, because there is always a unique int return value for the incoming external array, so we pursue complete “pure” and complete What is the purpose of not using variables?
To completely eliminate immutable variables under pure functions, we can do this:
tailrecfunsum(array: IntArray, current: Int = 0, index: Int = 0): Int {
if (index < 0 || index >= array.size) return current
return sum(array, current + array[index], index + 1)
}
We have written an exit condition. When index is abnormal, which means that there is nothing to add, current is returned directly, which is the current value that has been calculated; in other cases, the sum of current and the value of the current index is directly returned, and then Add the sum of all values after index + 1. This example is already very simple, but functional and recursive thinking will inevitably make people who learn traditional OOP need to think more.
Of course, as a kotlin developer, I did not hesitate to use the kotlin language feature tailrec to help optimize tail recursion. Otherwise, this function will throw a StackOverFlowError when encountering a fairly long list.
Function first class citizen
Many object-oriented languages usually use this to explicitly access the properties or methods of objects, and some languages omit writing this. In fact, in the implementation behind many language compilers, “calling object members” is usually changed into “Add an additional this variable to the member function”.
It can be seen that it is the function that plays an important role. It is better to go one step further. The function is a first-class citizen, and the object is just a structure. In this way, in a pure function, you will not use this at all, and you will not even use the object in many cases.
The so-called first-class citizen means that the function contains the object, rather than the object containing the function, and the object may not even be needed (an outrageous argument). The following is an example, which is a common business appeal:
UserService receives the user id and provides two functions to obtain the user token and the user’s local storage
ServerService requires server IP and port, and provides two capabilities: obtaining token through secret and obtaining user data through user token.
UserData is a user data class that can receive parent layout parameters to build UI data for display
Doesn’t it seem like these things are getting pretty complicated? But in fact, there are not many lines of real code written, and a lot of code is used to define types! This is why most of the examples that you can see showing functional expressions are implemented in js, because the type system of js is very weak, so it is very convenient to write functional expressions.
The example I use kt here is to write a lot of type marking code, because I have extremely high requirements for explicitly declaring types. If you like, you can also completely hide the type and rely on compiler reasoning, like this, Everything becomes concise, and writing is not much different from regular OOP.
val userService = { userId: Int ->
val tokenService = { password: String -> TODO() }
val localDbService = { dbPassword: String -> TODO() }
tokenService to localDbService
}
val serverService = { ip: String, port: Int ->
val tokenService = { serverSecret: String -> TODO() }
val userService = { userToken: String -> TODO() }
tokenService to userService
}
But the difference is that if you look at the above code, there is no class/structure at all, because the variables are all stored in the function body!
In terms of usage, the usage of the two methods is actually very similar, but you can see that we have completely abandoned the existence of classes! Even in future versions of kotlin, if this kind of code is always compiled into invokeDynamic in bytecode, then in this way even the existence of classes in bytecode can be avoided! (Of course, it will be desugarized into static inner classes in Android DEX)
// OOPval userService = UserService(id = 0)
val serverService = ServerService(ip = "0.0.0.0", port = 114514)
val userToken = userService.userToken(password = "undefined")
val userData = serverService.getUser(userToken)
val uiData = userData.uiData(parentLayoutParameters)
// functionalval (userTokenService, _) = userService(0)
val (_, userDataService) = serverService("0.0.0.0", 114514)
val userToken = userTokenService("undefined")
val userData = userDataService(userToken)
val uiData = userData(parentLayoutParameters)
BTW, the functional argument here does not include a name, which is mainly not supported by kt now. . .
Currying
In the above example, we can actually see that the existence of a class is not necessary. The essence of a class is actually just a function with some parameters preset. The problem that currying needs to solve is how to implement “preset” more easily. The ability to set some parameters”. After currying a function, a multi-parameter function is allowed to be passed in multiple times. For example, foo(a, b, c, d, e)it can become foo(a, b)(c)(d, e)a continuous function call like this.
In the following example, I will give an example of calculating weight:
funweight(t: Int, kg: Int, g: Int): Int {
return t * 1000_000 + kg * 1000 + g
}
After currying it:
val weight = { t: Int ->
{ kg: Int ->
{ g: Int ->
t * 1000_000 + kg * 1000 + g
}
}
}
Here we can find that currying actually makes the implementation more complicated. However, it is usually implemented through bind in js. Kt also has an open source currying library from the popular github. Using these can reduce the cost of writing currying to a certain extent. The complexity of the code.
The purpose of Skiplang is on the homepage of its website, A programming language to skip the things you have already computed. In the case of pure functions, it means knowing the input state, then the output state is uniquely determined. This situation is very suitable for Caching, if the input value has been calculated, the cached output value can be returned directly.
In the case of pure functions, it means that operations can be highly parallel. In skipplan, multiple asynchronous threads are not allowed to share variable variables, and naturally there will be no asynchronous locks and other things, thus ensuring the absolute safety of asynchronous .
personal reflections
The benefits of pure functions are very attractive, but developers often don’t like to use pure functions. Some common reasons may be:
Concerns about performance : Pure functions are not allowed to modify variables, and are only allowed to create a large number of variables through copy and other methods; the compiler needs to perform radical tail recursion optimization.
Developer awareness is weak : Most developers who come from schools will only use the set of OOP taught by their teachers. If they want to cultivate the transformation of OOP into functional style, many developers will usually find it difficult. Therefore, they think that traditional OOP is simple and mainstream. There’s no need to learn anything new.
Although I am very passionate about pure functions, I am not a radical pure functionist. I partially agree with them in my daily work. When it comes to kotlin programming, the philosophy I usually adhere to is:
Classes can be used and functions can be defined in classes, but mutable members are not allowed.
Mutable local variables can be used (but not recommended), but sharing between multiple threads is not allowed