

Flow in Kotlin is an API specifically designed to handle asynchronous data flow. It is an implementation of the Functional Reactive Programming FRP paradigm in Kotlin and is deeply integrated with Kotlin’s coroutines. It is the first solution to deal with asynchronous data flow problems in Kotlin. Get to know Flow today and learn how to use it.
Hello, Flow!
The old rule is that when you learn a new thing, you should always start with a basic “Hello, world” to quickly get started and experience it, so as to have a first impression. Let’s start the Flow journey with a simple “Hello, Flow!”:
fun main() = runBlocking {
val simple = flow {
listOf("Hello", "world", "of", "flows!")
.forEach {
delay(100)
emit(it)
}
}
simple.collect {
println(it)
}
}
//Hello
//world
//of
//flows!
Here, a data flow Flow<String> that generates String asynchronously is created. It will generate a String from time to time, then collect the data generated by this data flow and consume the outgoing String object.
It can be seen that Flow is essentially a producer-consumer model . The outgoing data is generated by the producer and eventually consumed by the consumer. You can think of Flow as a conveyor belt in a production line . Products (data) are constantly flowing on it, processed at each station, and finally formed and consumed by consumers. From this small example, we can see the three elements of the Flow API: the upstream of the data flow is to create Flow (producer); the midstream is the change operation (data processing and processing); the downstream is to collect data (consumer), we will do it one by one Learn in detail.
CreateFlow
Flow is a producer, and creating a Flow means putting data on a conveyor belt. The data can be basic data or collections, or data generated in other ways, such as network or callbacks or hardware. The API for creating Flow is called the flow builder function.
Create a flow with a collection
This is the simplest way to create a Flow. There are two. One is flowOf, which is used to create from a fixed number of elements. It is mostly used for examples and is basically not used in practice:
val simple = flowOf("Hello", "world", "of", "flows!")
simple.collect { println(it) }
Or, convert the existing collection to Flow through asFlow , which is more practical:
listOf("Hello", "world", "of", "flows!").asFlow()
.collect { println(it) }
(1..5).asFlow().collect { println(it) }
Universal flow builder
The most common flow builder is flow {…} , which is the most common and commonly used constructor. Just call emit in the code block . This code block will run in the coroutine, so the suspend function can be called in this code:
fun main() = runBlocking {
val simple = flow {
for (i in 1..3) {
delay(100)
println("Emitting: $i")
emit(i)
}
}
simple.collect { println(it) }
}
//Emitting: 1
//1
//Emitting: 2
//2
//Emitting: 3
//3
This is a code block. As long as emit is called to generate data, it can also call the suspend function, so it is very practical. For example, it can perform network requests, emit after the request comes back, etc.
terminal operator
Data flows from the producer until the consumer collects the data for consumption, and it is meaningful only when the data is consumed. Therefore, Terminal flow operators are also required. It should be noted that the terminal operator is the end point of Flow and is not considered inside the Flow conveyor belt. Therefore, terminal operations are all suspending functions. The caller needs to be responsible for creating a coroutine to call these suspending terminal operators normally.
There are three common terminal operations:
- collect is the most versatile, it can execute a code block, and the parameter is the data flowing out of Flow.
- Convert to Collections , such as toList and toSet , etc., which can easily convert the collected data into collections
- Take a specific value, such as first() only takes the first one, last only takes the last one, and single only takes one data (no data or more than one data will throw an exception.
- Dimensionality reduction (or aggregation accumulate) operations, such as fold and reduce . Folding and reduction can reduce the dimensionality of the data flow, such as summation, product, maximum and minimum values, etc.
- Count is actually a type of dimensionality reduction, returning the number of data in the data stream. It can also be combined with filtering to calculate the number of data after certain filtering conditions.
fun main() = runBlocking {
val simple = flow {
for (i in 1..3) {
delay(100)
println("Emitting: $i")
emit(i)
}
}
simple.collect { println(it) }
println("toList: ${simple.toList()}")
println("first: ${simple.first()}")
println("sum by fold: ${simple.fold(0) { s, a -> s + a }}")
}
Output:
Emitting: 1
1
Emitting: 2
2
Emitting: 3
3
Emitting: 1
Emitting: 2
Emitting: 3
toList: [1, 2, 3]
Emitting: 1
first: 1
Emitting: 1
Emitting: 2
Emitting: 3
sum by fold: 6
These terminal operators are simple and easy to understand. You will know how to use them after taking a look at the examples. What needs attention is first() and single(). First only receives the first one in the data stream, while single requires that the data stream can only have one data (no or more than one will throw an exception). The more interesting one is last(). The data flow is a stream, a product conveyor belt. Usually it is called a data flow when it refers to an unlimited or uncertain amount of data. So where does the last data come from? Usually last is meaningless. Last can only come in handy when we know that the producer of the stream only produces a limited amount of data, or uses some restrictive mutation operators.
Another thing to note is the difference between fold and reduce. The difference here is the same as the operation on the set. Fold can provide an initial value and return the initial value when the stream is empty; while reduce has no initial value and will throw an exception when the stream is empty. .
mutating operator
During the data flow process, data can be transformed from one data type to another. This is Transformation, which is the most flexible and powerful aspect of data flow. This is similar to the transformation of collections .
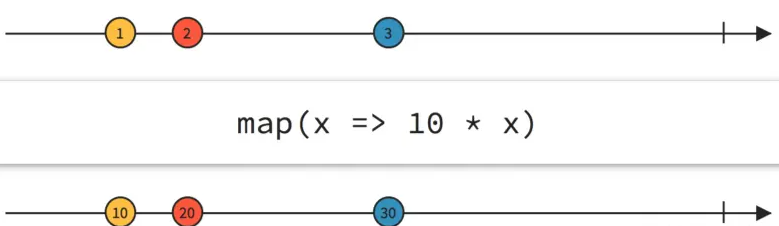
Convert
The most common change is conversion, that is, converting from one data type to another. Of course, map is the most commonly used , and there is also the more general transform . They can convert data in the data flow from one type to another, such as converting Flow to Flow. The difference is that map is a rigid conversion, one object goes in, and another object comes out as the return value; but transform is more flexible, it does not use new types as return values, it can generate (emit) new data like the upstream producer. , can even generate (emit) multiple new data, it is very powerful, all other transformation operators are implemented based on transform.
fun main() = runBlocking {
val simple = flow {
for (i in 1..3) {
delay(100)
println("Emitting: $i")
emit(i)
}
}
simple.map { " Mapping to ${it * it}" }
.collect { println(it) }
simple.transform { req ->
emit(" Making request $req")
emit(performRequest(req))
}.collect {
println(it)
}
}
fun performRequest(req: Int) = "Response for $req"
The output is:
Emitting: 1
Mapping to 1
Emitting: 2
Mapping to 4
Emitting: 3
Mapping to 9
Emitting: 1
Making request 1
Response for 1
Emitting: 2
Making request 2
Response for 2
Emitting: 3
Making request 3
Response for 3
There is also an operator withIndex which is similar to mapIndexed in the collection . Its function is to turn the element into IndexedValue, so that the element and the index of the element can be obtained later, which is more convenient in some scenarios.
limit
The data in the data stream is not necessarily required, so the data elements usually need to be filtered. This is the restrictive operator. The most common one is filter . This is similar to the restrictive operation of the set:
- filter converts data into Boolean type to filter the data stream.
- distinctUntilChanged filters duplicate elements in the data stream.
- drop discards a certain number of previous elements.
- take only returns a certain number of elements in the front of the stream. When the number is reached, the stream will be canceled. Note that take and drop are opposite.
- debounce only retains elements in the stream within a certain timeout interval. For example, if the timeout is 1 second, only the latest element when 1 second is reached will be returned. The elements before this element will be discarded. This is very useful in blocking crazy clicks in flash sale scenarios, or blocking crazy requests in a service. Only take the latest elements within a certain time interval and intercept invalid data.
- Sample takes elements at a certain time interval, which is similar to debounce. The difference is that debounce will return the last element, while sample does not necessarily. It depends on whether the last element of the interval can fall within a time interval.
@OptIn(FlowPreview::class)
fun main() = runBlocking {
val constraint = flow {
emit(1)
delay(90)
emit(2)
delay(90)
emit(3)
delay(1010)
emit(4)
delay(1010)
emit(5)
}
constraint.filter { it % 2 == 0 }
.collect { println("filter: $it") }
constraint.drop(3)
.collect { println("drop(3): $it") }
constraint.take(3)
.collect { println("take(3): $it") }
constraint.debounce(1000)
.collect { println("debounce(1000): $it") }
constraint.sample(1000)
.collect { println("sample(1000): $it") }
}
Look carefully at their output to understand what they do:
filter: 2
filter: 4
drop(3): 4
drop(3): 5
take(3): 1
take(3): 2
take(3): 3
debounce(1000): 3
debounce(1000): 4
debounce(1000): 5
sample(1000): 3
sample(1000): 4
It should be noted that debounce and sample are Preview APIs and need to be added with Preview annotations .
The midstream change operators are still part of the flow, and they all still run in the context of Flow. Therefore, within these operators, like the builder of the flow, they can directly call other supsend functions, even other time-consuming ones. , all blocking functions can be called. There is no need to specifically create context for upstream and midstream.
Flow has many operators, and we need to pay attention to distinguishing between midstream operators and downstream terminals. Just look at the return types of these functions. The return type is specific data and must be the downstream terminal operator; for upstream producers and midstream change operators, the return value must be a Flow.
Advanced operators
The operators mentioned above are all for a certain stream itself, but in most scenarios one stream is obviously not enough. We need to operate multiple streams, and then we need to use some advanced operators.
Merge multiple streams
It is impossible to process multiple streams one by one. It is more convenient to merge them into one stream. There are the following merging methods:
- Merge merges multiple streams with the same data type into one stream . Note that the data types must be the same before they can be merged, and the order of elements after the merge is unknown, that is, the order of elements of the original streams will not be retained. There is no limit on the number of merged streams.
- Glue zip When you want to align the elements of two streams and glue them into one element , you can use zip . When either stream ends or is cancelled, zip will also end. Can only be glued two by two.
- Combination combine combines the latest elements of each stream in the multi-channel stream into new data to form a new stream, whose elements are generated by converting each element with the latest element of each stream . At least 2 streams are required, and a maximum of 5 streams are supported.
Use a to feel their effect:
fun main() = runBlocking {
val one = flowOf(1, 2, 3)
.map(Int::toString)
.onEach { delay(10) }
val two = flowOf("a", "b", "c", "d")
.onEach { delay(25) }
merge(one, two)
.collect { println("Merge: $it") }
one.zip(two) { i, s -> "Zip: $i. $s" }
.collect { println(it) }
combine(one, two) { i, s -> "Combine $i with $s" }
.collect { println(it) }
}
Here is the output:
Merge: 1
Merge: 2
Merge: a
Merge: 3
Merge: b
Merge: c
Merge: d
Zip: 1. a
Zip: 2. b
Zip: 3. c
Combine 2 with a
Combine 3 with a
Combine 3 with b
Combine 3 with c
Combine 3 with d
You can see their differences through their output: merge is like connecting two water pipes, it is simple and requires no redundant processing, and is suitable for streams with the same data type (such as water); zip will align the two streams so that they can be aligned The elements are combined in pairs and it ends when they are not aligned.
However, combine must wait until the latest elements of each stream are collected before it can be converted into new data . Two is slower than one. When seeing the element “a” of two, the latest element of one is “2”, and then the element of one is “3”. “Come, the latest element of two is still “a”, then one stops at “3”, and the subsequent elements of two are all combined with “3”. Some students may have questions, why the “1” of one was discarded and no combination was found? Because it comes too early, when one’s “1” comes, two does not have an element yet, so it will definitely wait, but when two’s first element “a” comes, the latest element of one is already “2”, one emits an element every 10, and two emits an element every 25, so when the first element of two arrives, the second element of one has already arrived. It is the latest, so it will be used when combining it. Combine must collect the latest elements of each stream before it can be synthesized.
To sum up, zip will align elements in order ; combine will collect the latest elements of each stream , first , and then take the latest elements of each stream . You can run the example by yourself, modify the delay time, and see the difference in the output to deepen your understanding.
Flatten
A Flow is an asynchronous data flow, which is equivalent to a conveyor belt or pipeline, on which goods (specific data) flow. Under normal circumstances, regular data (objects) are flowing inside Flow, but Flow itself is also an object, so it can also be nested and treat the flow as the data of another flow, such as Flow<Flow<Int>>, this is Flow of Flows of Int. Flow is a data flow, and the final consumer needs specific data, so for nested Flow of Flows, it is usually necessary to flatten it before passing it to the terminal operator to obtain a falttered Flow (that is, from Flow< Convert Flow<Int>> to Flow<Int>), which can be consumed by the terminal. The functions starting with flat in the operator are all used for flattening, and there are mainly two types: one is to flatten the flatten system , and the other is to first change and then flatten the flatMap system .
flatten directly
The most intuitive flattening is to flatten the already nested Flow of Flows, so that the terminal operator can normally consume the data in the Flow. There are two APIs that can do flattening:
- flattenConcat flattens the nested Flow of Flows into one Flow. Each flow in the inner layer is spliced together in order, serially. For example, in Flow of 4 Flows, if there are four pipes in the inner layer, it becomes “Inner Layer 1” -> “Inner Layer 2” -> “Inner Layer 3” -> “Inner Layer 4”.
- flattenMerge flattens the Flow of Flows into one Flow. All Flows in the inner layer mix elements into new pipes in a concurrent manner. It is a concurrent mixing, which is equivalent to four pipes pouring water into another pipe at the same time. The order will be messed up.
@OptIn(ExperimentalCoroutinesApi::class)
fun main() = runBlocking {
val flow2D = flowOf("Hello", "world", "of", "flow!")
.map { it.toCharArray().map { c -> " '$c' " }.asFlow() }
.flowOn(Dispatchers.Default)
flow2D.collect { println("Flow object before flatten: $it") } // Data in flow are Flow objects
println("With flattenConcat:")
flow2D.flattenConcat()
.collect { print(it) }
println("\nWith flattenMerge:")
flow2D.flattenMerge()
.collect { print(it) }
}
//Flow object before flatten: kotlinx.coroutines.flow.FlowKt__BuildersKt$asFlow$$inlined$unsafeFlow$3@1b0375b3
//Flow object before flatten: kotlinx.coroutines.flow.FlowKt__BuildersKt$asFlow$$inlined$unsafeFlow$3@e580929
//Flow object before flatten: kotlinx.coroutines.flow.FlowKt__BuildersKt$asFlow$$inlined$unsafeFlow$3@1cd072a9
//Flow object before flatten: kotlinx.coroutines.flow.FlowKt__BuildersKt$asFlow$$inlined$unsafeFlow$3@7c75222b
//With flattenConcat:
//'H' 'e' 'l' 'l' 'o' 'w' 'o' 'r' 'l' 'd' 'o' 'f' 'f' 'l' 'o' 'w' '!'
//With flattenMerge:
// 'H' 'e' 'l' 'l' 'o' 'w' 'o' 'r' 'l' 'd' 'o' 'f' 'f' 'l' 'o' 'w' '!'
As can be seen from the output, if there is a Flow object inside the Flow, it cannot be used. flattenConcat connects the inner streams together serially. But the output of flattenMerge seems inconsistent with the document description, and there is no concurrent mixing.
Convert first then flatten

Most of the time, there are no ready-made nested Flows of Flows for you to flatten. More often, we need to convert the element into a Flow ourselves. First generate the Flow of Flows, and then flatten it with a defined The API can be used directly:
- flatMapConcat first changes the data in the Flow. This change must change from an element to another Flow. At this time, it becomes a nested Flow of Flows, and then flattens it serially into a Flow.
- flatMapLatest first changes the latest data in the Flow. This change must change from an element to another Flow. At this time, the inner flow generated by the previous conversion will be canceled. Although the result is also nested, there is only one inner flow, which is the original flow. The flow generated by the latest element transformation in Flow. Then flatten it. This actually does not need to be flattened, because there is only one inner stream, and the data in it is the final flattened data.
- flatMapMerge is the same as flatMapConcat, except that the nested inner streams are spliced concurrently during flattening.
You can understand their function by looking at :
@OptIn(ExperimentalCoroutinesApi::class)
fun main() = runBlocking {
val source = (1..3).asFlow()
.onEach { delay(100) }
println("With flatMapConcat:")
var start = System.currentTimeMillis()
source.flatMapConcat(::requestFlow)
.collect { println("$it at ${System.currentTimeMillis() - start}ms from the start") }
println("With flatMapMerge:")
start = System.currentTimeMillis()
source.flatMapMerge(4, ::requestFlow)
.collect { println("$it at ${System.currentTimeMillis() - start}ms from the start") }
println("With flatMapLatest:")
source.flatMapLatest(::requestFlow)
.collect { println("$it at ${System.currentTimeMillis() - start}ms from the start") }
}
fun requestFlow(x: Int): Flow<String> = flow {
emit(" >>[$x]: First: $x")
delay(150)
emit(" >>[$x]: Second: ${x * x}")
delay(200)
emit(" >>[$x]: Third: ${x * x * x}")
}
The output is more:
With flatMapConcat:
>>[1]: First: 1 at 140ms from the start
>>[1]: Second: 1 at 306ms from the start
>>[1]: Third: 1 at 508ms from the start
>>[2]: First: 2 at 613ms from the start
>>[2]: Second: 4 at 765ms from the start
>>[2]: Third: 8 at 969ms from the start
>>[3]: First: 3 at 1074ms from the start
>>[3]: Second: 9 at 1230ms from the start
>>[3]: Third: 27 at 1432ms from the start
With flatMapMerge:
>>[1]: First: 1 at 130ms from the start
>>[2]: First: 2 at 235ms from the start
>>[1]: Second: 1 at 284ms from the start
>>[3]: First: 3 at 341ms from the start
>>[2]: Second: 4 at 386ms from the start
>>[1]: Third: 1 at 486ms from the start
>>[3]: Second: 9 at 492ms from the start
>>[2]: Third: 8 at 591ms from the start
>>[3]: Third: 27 at 695ms from the start
With flatMapLatest:
>>[1]: First: 1 at 807ms from the start
>>[2]: First: 2 at 915ms from the start
>>[3]: First: 3 at 1021ms from the start
>>[3]: Second: 9 at 1173ms from the start
>>[3]: Third: 27 at 1378ms from the start
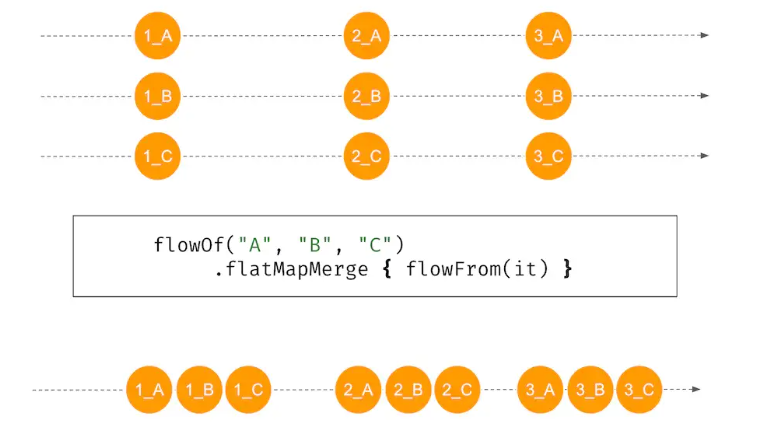
In this example, the original Flow is an Int value, which is converted into a string stream Flow<String>. From the output, you can see that flatMapConcat is indeed a serial splicing, and flatMapMerge is a concurrent mix, which does not guarantee the order of elements in the internal Flow. Look carefully at the output of flatMapLatest. Whenever a new value is generated in the original Flow, the flows generated by the previous transformation will be cancelled. They have not finished running (only the first element flows out). The last element “3” of the original flow completely flows out of the flattened flow.
There are many flattening functions that are easy to learn. In fact, there is a very simple way to distinguish them: functions with the word Map convert elements into Flow first and then flatten them; functions with Concat are used to serially splice nested inner flows. ; And with Merge , the inner flow is mixed concurrently . When using it, if you want to ensure the order, use the function with Concat; if you want concurrency, be more efficient, and don’t care about the order of elements, then use the function with Merge.
Flow is cold flow
There are hot and cold data streams . Cold stream means that the consumer starts to produce data when it starts to receive data. In other words, the upstream starts only after the entire link between the producer and consumer is established. Producing data; Hot stream, on the contrary, produces data regardless of whether anyone is consuming it or not. A very vivid metaphor is that cold streaming is like a CD, you can listen to it at any time, and as long as you play it, all the music on the CD will be played from the beginning; hot streaming is like a radio broadcast, it will always play regardless of whether you listen to it or not. It is broadcast according to its rhythm. If you don’t listen today, you will miss today’s data. If you listen today and tomorrow, the content you hear will be different.
Kotlin’s Flow is a cold flow . In fact, it can also be seen from the above examples. In each example, only one Flow object is created, and then there are multiple collects, but each collect can get the complete data in Flow . This It’s a typical cold flow . In most scenarios, what we need is cold flow.
Further reading Hot and cold data sources .
Differences from ReactiveX
Flow is an API for processing asynchronous data flows and an implementation of the functional reactive programming paradigm FRP. But it is not the only one. The more popular RxJava is also an FRP-compliant asynchronous data stream processing API. It appeared earlier, has a more active community, richer resources, and higher popularity. It is basically a must for every Android project. It is also a required dependency library for interviews.
Because Kotlin is a derivative language based on the JVM, it is interoperable with Java and can be used together. So RxJava can be used directly in Kotlin without any modifications. But after all, RxJava is a native Java library, and the large amount of syntactic sugar in Kotlin is still very fragrant, so RxKotlin is born . RxKotlin is not a reimplementation of the ReactiveX specification . It is just a lightweight glue library that makes RxJava more Kotlin-friendly through extension functions and Kotlin’s syntax sugar, making it smoother to use RxJava in Kotlin. But the core is still RxJava, and the implementation of concurrency still uses threads.
So what is the difference between Flow and RxJava? The difference is that Flow is a pure Kotlin thing. The idea behind them is the same. They are both asynchronous data flow and FRP, but Flow is native. It is closely integrated with the characteristics of Kotlin. For example, its concurrency uses coroutines. Channel is used for communication. The suggestion is that if you are familiar with RxJava and it is legacy code, then there is no need to change to Flow; but if it is a newly developed purely new function that does not interact with legacy code and does not conflict with the architecture, still It is recommended to go directly to Flow.
When to use Flow
Each tool has its specific application scenarios. Although Flow is good, it cannot be abused. You must understand the essence of the problem from an architectural perspective and use it only if it meets the requirements. Flow is an API for processing asynchronous data flows and is a powerful tool under the FRP paradigm. Therefore, it is appropriate to use Flow only when the core business logic is driven by asynchronous data flow. Nowadays, most end-end (front-end, client and desktop) GUI applications are responsive. The user inputs, or the server pushes data, and the application responds, so they all conform to the FRP paradigm. Then the focus is on data flow. If the data is connected into a stream, you can use Flow. For example, user output, click event/text input, etc. This does not happen only once, so it is a data flow (event flow). Core business data, such as news lists, product lists, article lists, comment lists, etc., are all flows and can all use Flow. Configuration, settings and database changes are also streamed.
However, a single article display or a product display is not a stream. There is only one article. Even if a stream is used, it has only one data, and we know that it has only one data. In this case, there is no need to use Flow, just use a supsend request.
Using Flow in Android

The official language for Android development has become Kotlin, and Android applications are also very consistent with the FRP paradigm, so it is natural to use Flow for scenarios involving asynchronous data flow.
Further reading:
- What is Flow in Kotlin and how to use it in Android Project?
- Kotlin flows on Android
- Learn Kotlin Flow by real examples for Android