

Purely using LLMs in the enterprise will not produce very good results because they will not encode the specific domain-specific knowledge about the organization’s activities that actually brings value extraction to the information dialogue interface. Many companies try to optimize this process through RAG, and more and more people are constantly researching in the direction of RAG. Today we will discuss GraphRAG, which combines knowledge graphs and graph databases as large models with the latest private knowledge systems. technology, analyzing how it unlocks the potential of RAG to enhance the accuracy and relevance of LLM in answering complex questions.

What is RAG?
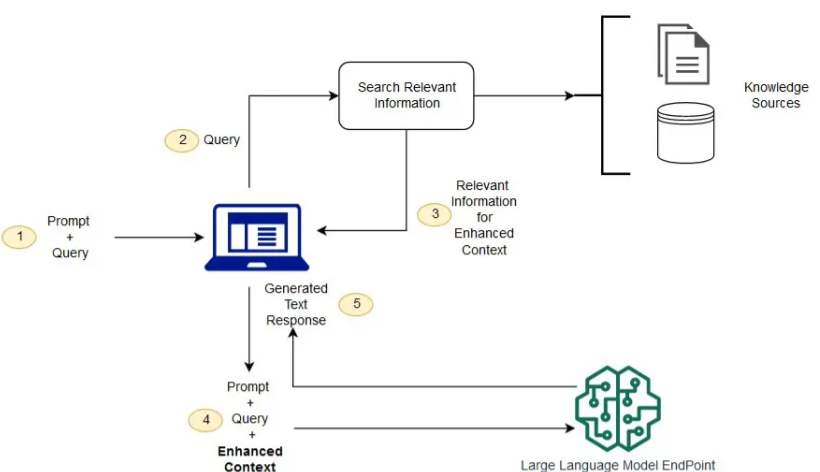
RAG is a natural language query method used to enhance existing LLM with external knowledge, so if the question requires specific knowledge, the answer to the question will be more relevant. It includes a Retrieve Information component that obtains additional information from external sources, also known as “base context,” and then feeds it to the LLM prompt to more accurately answer the required questions.
This method is the cheapest and most standard way to enhance LLM with additional knowledge to answer the question. Additionally, it has been shown to reduce the tendency of LLMs to hallucinate, as this generation adheres more to information from context, which is generally reliable. Due to this nature of the method, RAG becomes the most popular method for enhancing the output of generative models.
In addition to question answering, RAG can be used for many natural language processing tasks, such as information extraction from text, recommendation, sentiment analysis, and summarization.
But when RAG solves problems, it will also perform very poorly:
- Basic RAG makes it difficult to connect the dots. This occurs when answering a question requires traversing disparate information through shared attributes to provide new combined insights.
- Basic RAG performs poorly when required to comprehensively understand summarized semantic concepts of large data collections or even single large documents.
GraphRAG
GraphRAG is a technology that combines knowledge graphs and large language models (LLM) to improve the capabilities of question answering systems. Microsoft researchers announced GraphRAG, a new approach to augmenting AI-driven question answering systems with AI-generated knowledge graphs. GraphRAG technology requires large language models to create knowledge graphs based on private data sets, thereby improving the question and answer process.
GraphRAG leverages graph embeddings in the results of graph neural networks (GNNs) to enhance text embeddings to improve user query response reasoning. This method is called soft-prompting and is a prompting technology. In addition, GraphRAG is used to train LLMs to learn through graph-based data representations without directly providing data, which enables the model to access a large amount of structured knowledge.

How to perform RAG?
To implement a Graph RAG for question answering, you need to choose what information can be sent to the LLM. This is usually done by querying the database based on the intent of the user’s question. The most suitable database for this purpose is a vector database, which captures the underlying semantics, syntactic structures, and relationships between items in a continuous vector space through embeddings. Rich prompts contain user questions along with pre-selected additional information so the generated answers take it into account.
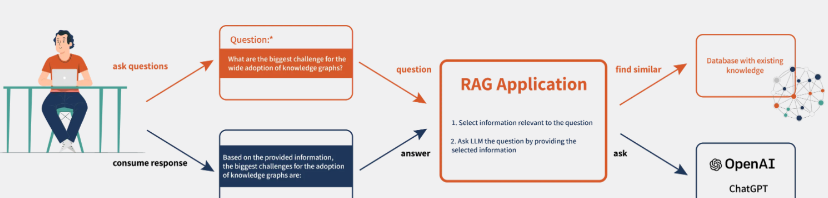
A simple Graph RAG can be simply implemented as follows:
- Use an LLM (or other) model to extract key entities from the problem
- Retrieve subgraphs based on these entities and drill down to a certain depth
- LLM is used to generate answers using the obtained context.
For example, with LLM orchestration tools like LlamaIndex, developers can focus on the orchestration logic and pipeline design of LLM without having to deal with many detailed abstractions and implementations themselves.
Therefore, using LlamaIndex, we can easily build Graph RAG and even integrate more complex RAG logic, such as Graph + Vector RAG.
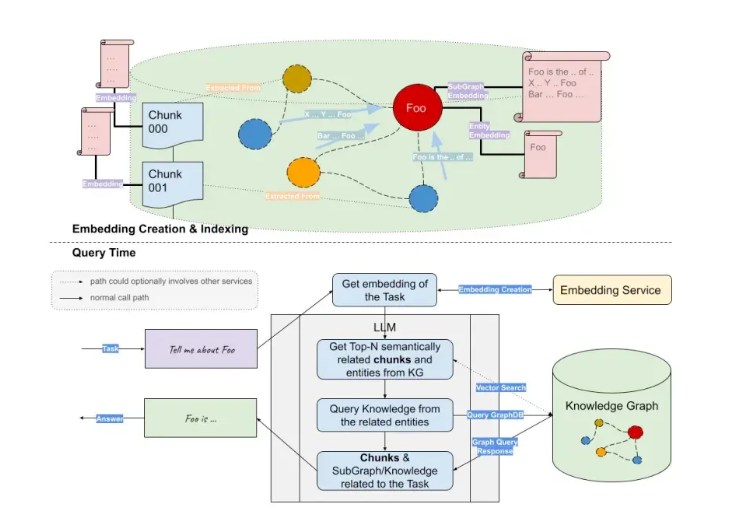
Although the basic implementation is simple, there are a number of challenges and considerations you need to consider to ensure good quality results:
- Data quality and relevance are critical to the effectiveness of Graph RAG, so questions such as how to get the most relevant content to send LLM and how much content to send should be considered.
- Dealing with dynamic knowledge is often difficult because vector indexes need to be constantly updated with new data. Depending on the size of the data, this may pose further challenges such as efficiency and scalability of the system.
- Transparency in generated results is important to make the system trustworthy and usable. There are some quick engineering techniques that can be used to stimulate the LLM to explain the source of the information contained in the answer.
Different types of Graph RAG
Graph RAG is an enhancement to the popular RAG method. Graph RAG includes a graph database that serves as the source of contextual information sent to LLM. Providing LLM with text chunks extracted from larger size documents may lack the necessary context, factual correctness, and linguistic accuracy, and the LLM cannot deeply understand the received text chunks. Rather than sending chunks of plain text documents to LLM, Graph RAG can also provide structured entity information to LLM, combining entity text descriptions with their many attributes and relationships, thereby encouraging LLM to generate deeper insights. With Graph RAG, each record in the vector database can have a rich contextual representation, improving the understandability of specific terms, so LLM can better understand a specific subject area. Graph RAG can be combined with standard RAG methods to get the best of both worlds – the structure and accuracy of graph representation combined with large amounts of textual content.
We can summarize several variants of Graph RAG based on the nature of the problem, the domain and the information in the existing knowledge graph:
- Graphs are stored as content : extract relevant document chunks and ask LLM to use them to answer. This diversity requires a knowledge graph containing relevant textual content and metadata, integrated with vector databases.
- Graph entity chaining as subject matter experts : Extract descriptions of concepts and entities relevant to a natural language (NL) question and pass them to LLM as additional “semantic context”. Ideally, descriptions should include relationships between concepts. This diversity requires a knowledge graph with a comprehensive conceptual model, including related ontologies, taxonomies, or other entity descriptions. The implementation requires or other mechanism to identify concepts relevant to the problem.
- Graphs as databases : Map (parts of) an NL problem to a graph query, execute the query and ask LLM to summarize the results. This variety requires a diagram that contains relevant factual information. Implementation of this pattern requires some kind of NL-to-graph query tool and entity linking.
Summarize
GraphRAG (Graph Retrieval-Augmented Generation) is an advanced method that combines graph database and retrieval enhancement generation technology. It has demonstrated its unique value and potential in a variety of application scenarios. By combining the powerful representation capabilities of graph databases and the understanding capabilities of large language models, with the further development of technology, the application scenarios of GraphRAG will become more extensive and in-depth.