

Preface
RAG is a natural language processing technology that combines the capabilities of retrieval (vector database) and generative artificial intelligence models to effectively improve the quality of information retrieval. We call it retrieval enhancement generation technology.
ChatGPTIt is a chat robot, so a chat robot based on a large model is a RAG application.
Naive RAG
Naive RAG refers to the most basic retrieval generation, including document segmentation, embedding, and semantic similarity search based on questions raised by users to generate retrieval content. In this article, we will sublimate our understanding and capabilities of RAG based on Naive RAG.
The advantage of Naive RAG is that it is simple, but the disadvantage is that its performance is relatively poor and its quality is not high. In this series, let us learn Advanced RAG together.
Semi-Structured Data
Semi Structured DataRAG of semi-structured data is Advanced RAGthe first article we study. So what is semi-structured data? This should be quite structured data, let’s first sort out these concepts.
- structured data
Information has a predefined structural format. For example, in Mysql, the rows and columns of the data table have predefined data respectively. This is typical structured data. Its advantage is that it is very easy to search and analyze.
- unstructured data
There is no specific format and structure, and it is mainly composed of text, pictures, multimedia, etc. Unstructured data is not easy to process uniformly, but this data is the key content that RAG needs to retrieve, which is very challenging.
- semi-structured data
Somewhere between structured and unstructured, it consists of a mixture of data from both formats. So how do we deal with it? For structured data, we can use DSL languages such as SQL to quickly solve problems. For unstructured data, we can split it and then embedding it for retrieval. But if our data is semi-structured data that is a mixture of structured and unstructured data. Splitting the document will destroy the table structure. At the same time, the tables and pictures need to be vectorized, and then semantic queries are performed.
PDF documents are examples of semi-structured data. It contains text, tables, pictures, etc. Wait a minute, let’s challenge how to build a RAG based on semi-structured data. The following components are mainly used: unstructured package, which helps us customize pipelines or streams to process elements such as text, charts, and pictures. There is also LangChain, which we use to build the entire RAG application. We use chromadb as the vector database.
Nvidia Equity Variable Statement
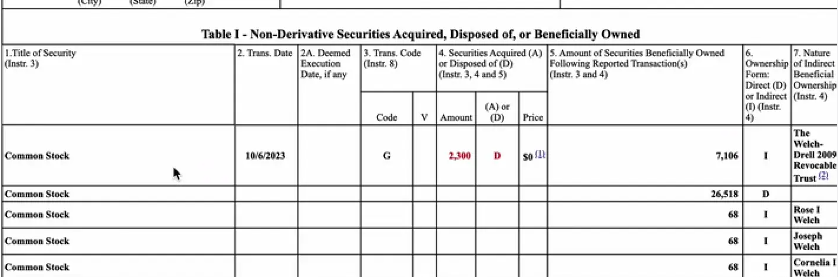
The semi-structured data processed in the demo comes from an equity change statement from Nvida . You can see its content from the screenshot below. It is relatively small and convenient for displaying structured charts and unstructured text. We have taken care of the effect.

Actual combat
- Install dependency packages
!pip install langchain unstructured[all-docs] pydantic lxml openai chromadb tiktoken -q -U
langchain is a RAG application development framework, unstructured supports semi-structured or unstructured data processing, pydantic can do data verification and parsing conversion, lxml can do xml parsing, ooenai is a large model, chromadb is a vector database, and tiktoken can count the number of tokens.
- Download the PDF file named statement_of_changes.pdf
!wget -o statement_of_changes.pdf https://d18rn0p25nwr6d.cloudfront.net/CIK-0001045810/381953f9-934e-4cc8-b099-144910676bad.pdf
- Install poppler-utils and tesseract-ocr
These two packages are system packages, used for extracting PDF file content and character recognition. The installation commands will differ depending on the system (mac/windows/linux)
!apt-get install poppler-utils tesseract-ocr
- Prepare LLM, here we use gpt4
import os
os.environ["OPENAI_API_KEY"] = ""
- coding
First, let’s use partition_pdf provided by the unstructured library to split the content in the PDF document into different types of elements.
from typing import Any
from pydantic import BaseModel
from unstructured.partition.pdf import partition_pdf
raw_pdf_elements = partition_pdf(
filename = "statement_of_changes.pdf",
extract_images_in_pdf=False,
infer_table_structure=True,
# chunk
chunking_strategy = "by_title",
max_characters=4000,
new_after_n_chars=3000,
combine_text_under_n_chars=2000,
image_output_dir_path="."
)
Let’s talk about the meaning of several parameters in the partition_pdf function. extract_images_in_pdf indicates whether to extract the images in the pdf, which is not processed here because there are no images in the current pdf. infer_table_structure indicates whether to extract table data, here is the processing. Judging from the code running, it triggers some model files and loads them. As you can see from the picture below, the microsoft/table-transformer-struct-recognition model is used, which requires the use of GPU resources, otherwise it will be very slow.
- Classify elements
category_counts = {}
for element in raw_pdf_elements:
category = str(type(element))
if category in category_counts:
category_counts[category] += 1
else:
category_counts[category] = 1
unique_categories = set(category_counts.keys())
category_counts
By traversing raw_pdf_elements, we get the type of each element. set helps us remove duplicates and get all categories. The category_counts dictionary contains the quantity information of each category.

As you can see from the picture above, there are 5 CompositionElements and 4 Tables. Next, we can put different contents into different processing containers based on these types to complete the sorting operation.
class Element(BaseModel):
type: str
text: Any
table_elements = []
text_elements = []
for element in raw_pdf_elements:
if "unstructured.documents.elemnts.Table" in str(type(element)):
table_elements.append(Element(type="table", text=str(element)))
elif "unstructured.documents.elments.CompositeElement" in str(type(element)):
text_elements.append(Element(type="text", text=str(element)))
print(len(table_elements))
print(len(text_elements))
The printing is 4 and 5. Let’s print the structured table again.
From the printed results, it can be seen that the corresponding table is recognized very reliably. table_elements[0] corresponds to the block in the figure below. We understand how unstructured parses the table.

Chain
LangChain builds a Chain to process data.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
#
prompt_text = """
You are responsible for concisely summarizing table or text chunk.
{element}
"""
prompt = ChatPromptTemplate.from_template(prompt_text)
model = ChatOpenAI(temperature=0,model="gpt-4")
summarize_chain={"element": lambda x: x} | prompt | model | StrOutputParser
#
#
tables = [i.text for i in table_elements]
table_summarizes = summarize_chain.batch(tables, {"max_concurrency": 5})
#
texts = [i.text for i in text_elments]
text_summarizes = summarize_chain.batch(texts, {"max_concurrency": 5})
Next, we use MultiVectorRetrieverthe built retrieval chain, which will associate the summary information and the original text information in a one-to-one parent-child relationship. In this way, both the original text and the summary information can be used, helping us improve the quality of RAG.
#
import uuid
#
from langchain.embeddings import OpenAIEmbeddings
#
from langchain.schema.document import Document
#
from langchain.storage import InMemoryStore
#
from langchain.vectorstores import Chroma
#
vectorstore = Chroma(collection_name="summaries", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
#
id_key="doc_id"
#
retriever = MultiVectorRetriever(
vectorstore = vectorstore,
docstore = store,
id_key=id_key
)
#
doc_ids = [str(uuid.uuid4()) for _ in texts]
#
summary_texts = [
Document(page_content=s, metadata={id_key:doc_ids[i]})
for i, s in enumerate(text_summaries)
]
#
retriever.vectorstore.add_documents(summary_texts)
#
retriever.docstore.mset(list(doc_ids, texts))
#
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content=s, metadata={id_key:table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
integrated
from langchain.schema.runnable import RunnablePassthrough
template = """Answer the question based only on the following context, which can include text and tables:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
## LLM
model = ChatOpenAI(temperature = 0, model="gpt-4")
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
implement
We asked questions based on the tabular data in the document. At a certain time, a transaction or change was made on a certain stock, and finally there were beneficiaries.
chain.invoke("How many stocks were disposed?Who is the beneficial owner?")

Note that we are using gpt4 here. You can switch to gpt-3.5-turbo, and you will find that it does not work as well.
Summarize
- MultiVectorRetriever
- unstructured
- chromadb and InMemoryStore