

The phi-series model is a lightweight artificial intelligence model launched by the Microsoft research team. It aims to achieve the goal of being “small and precise” and can be deployed and run on low-power devices such as smartphones and tablets. So far, the phi-3 model has been released. This series of blogs will introduce the initial phi-1 to phi-1.5, and then to the phi-2 and phi-3 models. This article introduces the phi-2 model.
Overview
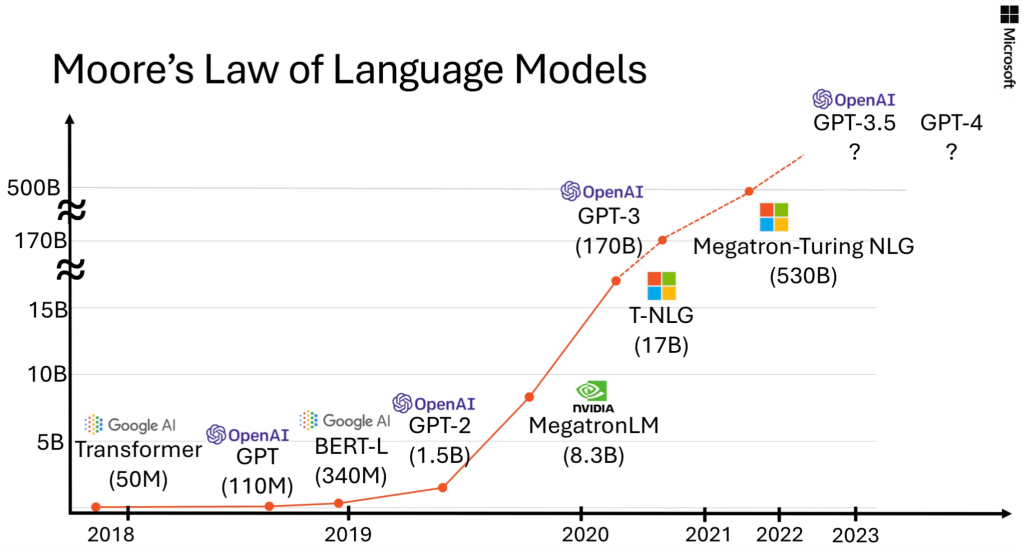
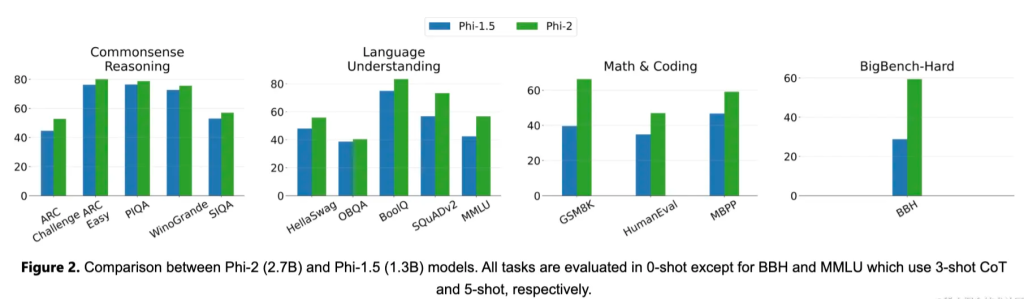
In the past few months, the machine learning foundation team of Microsoft Research has released a set of Small Language Models (SLMs) called “Phi”, which has achieved remarkable performance in various benchmark tests. Phi-1, which includes 1.3B parameters, achieves state-of-the-art performance on Python coding among existing SLMs (specifically on the HumanEval and MBPP benchmarks). and the 1.3B parameter model Phi-1.5 extended to common sense reasoning and language understanding, with performance comparable to models 5x larger.
This article introduces Phi-2, a 2.7B parameter language model that demonstrates excellent reasoning and language understanding capabilities, showing state-of-the-art performance among base language models with less than 13B parameters. In complex benchmarks, Phi-2 matches or exceeds models that are 25 times larger, thanks to new innovations in model scaling and training data curation. Phi-2’s compact size makes it an ideal experimental model for researchers, including experiments on mechanical interpretability, safety improvements, or fine-tuning for a variety of tasks. Phi-2 is available in the Azure AI Studio model catalog to facilitate language model research and development.

Key Highlights of Phi-2
The dramatic increase in the size of language models to hundreds of billions of parameters has unlocked a range of emerging capabilities and redefined the landscape of natural language processing. A question remains whether this emerging capability can be achieved at a smaller scale through strategic selection of training data, such as data selection.
Work on the Phi family of models aims to answer this question by training SLMs that are comparable to larger models (although still far from cutting-edge models). This article uses Phi-2 to break the expansion rules of traditional language models. There are two key insights:
First, training data quality is critical to model performance. This has been known for decades, but this article takes this insight to the extreme, focusing on data on “textbook quality”, continuing previous work “Textbook is all you need”. The training data mix for this article consists of synthetic datasets created specifically to teach models common sense reasoning and general knowledge, including science, everyday activities, and theory of mind. The training corpus is further enhanced with carefully curated web data that is filtered based on educational value and content quality. Second, use innovative techniques to expand, starting with the 1.3B parameter model Phi-1.5 and embedding its knowledge into the 2.7B parameter Phi-2. This scaled knowledge transfer not only accelerates training convergence, but also shows significant improvements in Phi-2 benchmark scores.
training details
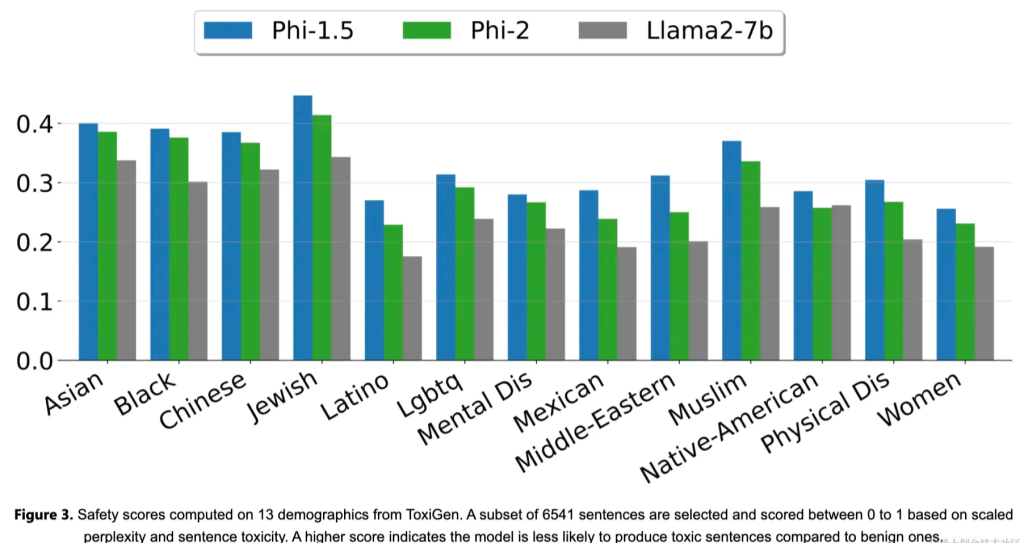
Phi-2 is a Transformer-based model that uses the next word prediction target and is trained with a mixture of NLP and encoding on multiple passes of synthetic and network data sets, totaling 1.4T tokens. Training took 14 days and used 96 A100 GPUs. Phi-2 is a base model that has not yet undergone reinforcement learning alignment with human feedback (RLHF) and has not undergone instruction fine-tuning. Nonetheless, we observe better performance in terms of toxicity and bias compared to aligned existing open source models (see Figure 3). This is consistent with what was observed in Phi-1.5 and is due to the authors’ tailored data curation techniques, please consult the previous technical report for more details.
Phi-2 Assessment
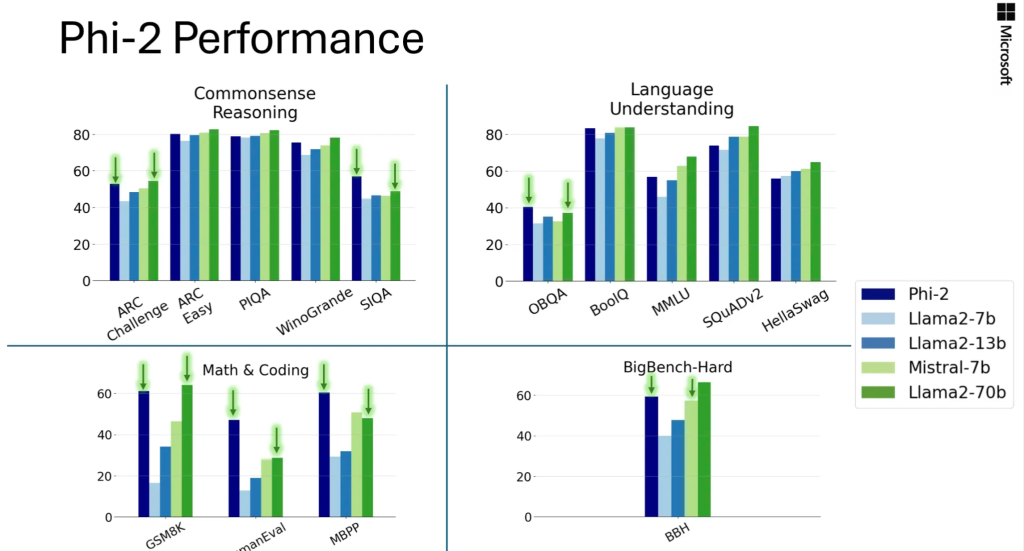
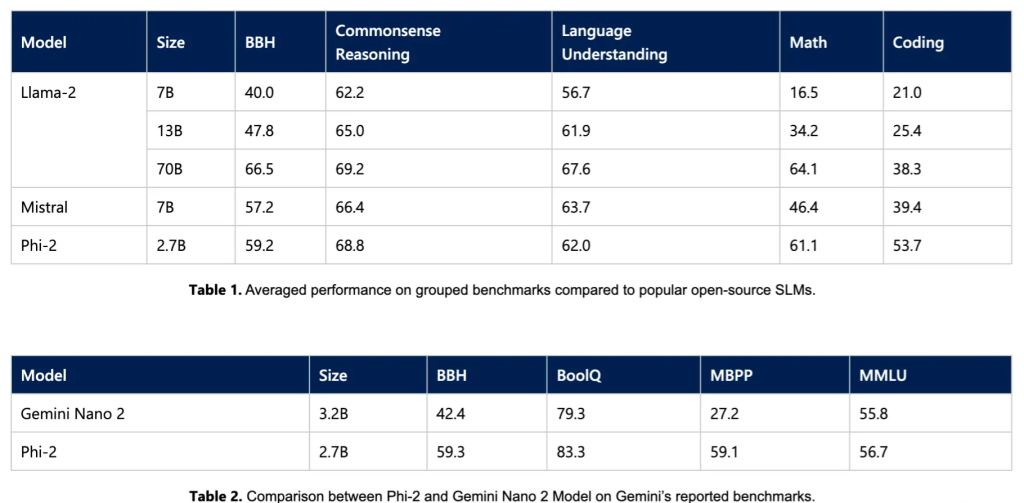
Below is a summary of how Phi-2 performs compared to popular language models on academic benchmarks. Benchmarks cover several categories, including Large Benchmark (BBH) (3-shot and CoT), Commonsense Reasoning (PIQA, WinoGrande, ARC, SIQA), Language Understanding (HellaSwag, OpenBookQA, MMLU (5-shot), SQuADv2 (2-shot), BoolQ), mathematics (GSM8k (8-shot)), and encoding (HumanEval, MBPP (3-shot)).
Phi-2, with only 2.7B parameters, outperforms the Mistral and Llama-2 models (which have 7B and 13B parameters respectively) in various synthetic benchmarks. Notably, Phi-2 performs better on multi-step reasoning tasks (i.e. coding and mathematics) compared to the Llama-2-70B model, which is 25 times larger. Additionally, despite being smaller, the Phi-2 matches or outperforms the recently announced Google Gemini Nano 2 in performance.
Of course, model evaluation faces some challenges, and many public benchmarks may leak into the training data. For Phi-1, the authors performed extensive purification studies to rule out this possibility, which can be found in the first report. The authors believe that the best way to judge a language model is to test it on specific use cases. Following this spirit, this paper also evaluates Phi-2 using several internal Microsoft proprietary datasets and tasks, again comparing it to Mistral and Llama-2. A similar trend can be observed, i.e., on average, Phi-2 outperforms Mistral-7B, which in turn outperforms the Llama-2 models (7B, 13B, and 70B).
In addition to these benchmarks, this paper also conducts extensive testing of commonly used tips in the research community. The observed behavior is consistent with expectations in the benchmark results. For example, this article tested the prompts used to explore a model’s ability to solve physics problems, recently used to evaluate the ability of the Gemini Ultra model, and obtained the following results:


Best Practices to Scale up
When scaling up, the author first gives some experimental results on the phi-1 model:
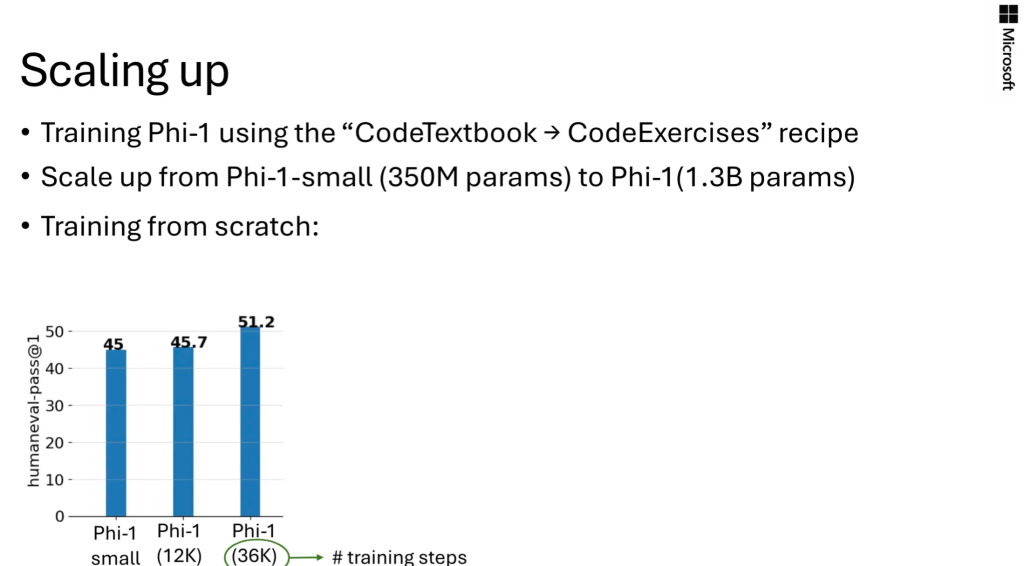
It can be seen that the longer the training times, the better the model performance, but the more time it takes. For this reason, the author tries to reuse the already trained small model weights in the large model, but will also face a challenge: how to extend the weights of the small model to the dimensions of the large model?
The author tried a method proposed in previous research, that is, using the formula in the figure below to map the number of layers:

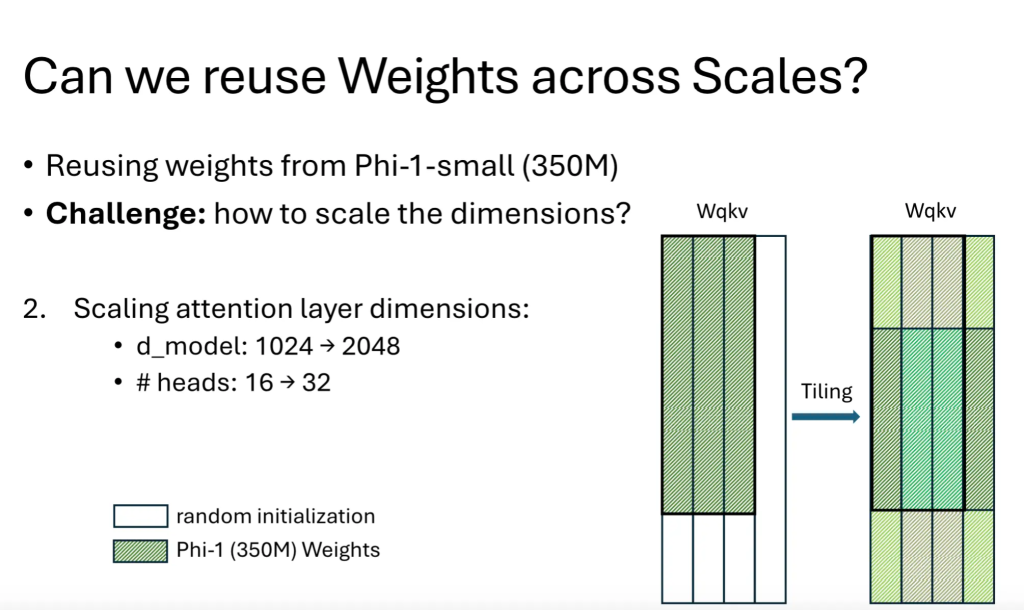
In terms of dimensions, retain those existing weights as part of the new large weight parameter matrix, and the remaining parts can be randomly initialized, as shown in the following figure:

After such reuse experiments, the experimental results are as follows:
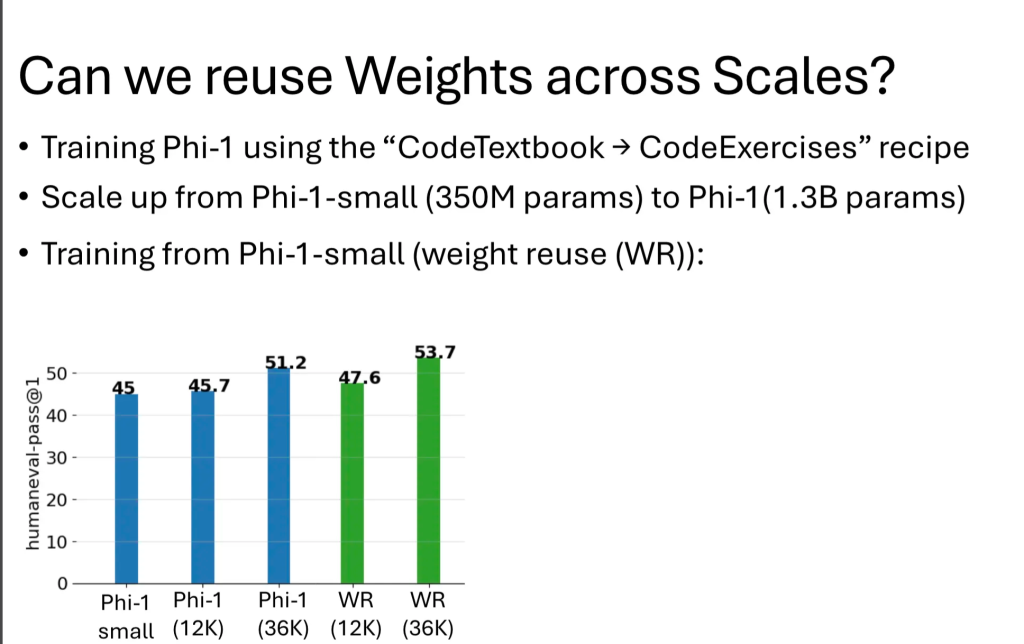
Another effective parameter inheritance method is tiling, as shown below:
The final performance obtained is as follows:
Summarize
A good, general-purpose SLM can be implemented in the following ways:
Generate and utilize “textbook quality” data compared to traditional web data;
Incorporate best practices for scaling to enhance overall performance.