

Visual language models can learn from images and text at the same time, so they can be used for a variety of tasks such as visual question answering and image description. In this article, we’ll take you through the world of visual language models: give you an overview, understand how they work, figure out how to find your destiny model, how to reason about it, and how to easily fine-tune it using the latest version of trl.
What is a visual language model?
The visual language model is a multi-modal model that can learn from images and text at the same time. It is a generative model. The input is images and text, and the output is text. The large visual language model has good zero-sample capabilities, good generalization capabilities, and can handle multiple types of images including documents, web pages, etc. It has a wide range of applications, including image-based chat, image recognition based on instructions, visual question answering, document understanding, image description, etc. Some visual language models can also capture spatial information in images. When prompted to detect or segment a specific object, these models can output bounding boxes or segmentation masks. Some models can also localize different objects or answer their relative or absolute positions. related questions. Existing large visual language models use a variety of methods in terms of training data, image encoding methods, etc., so their capabilities vary greatly.
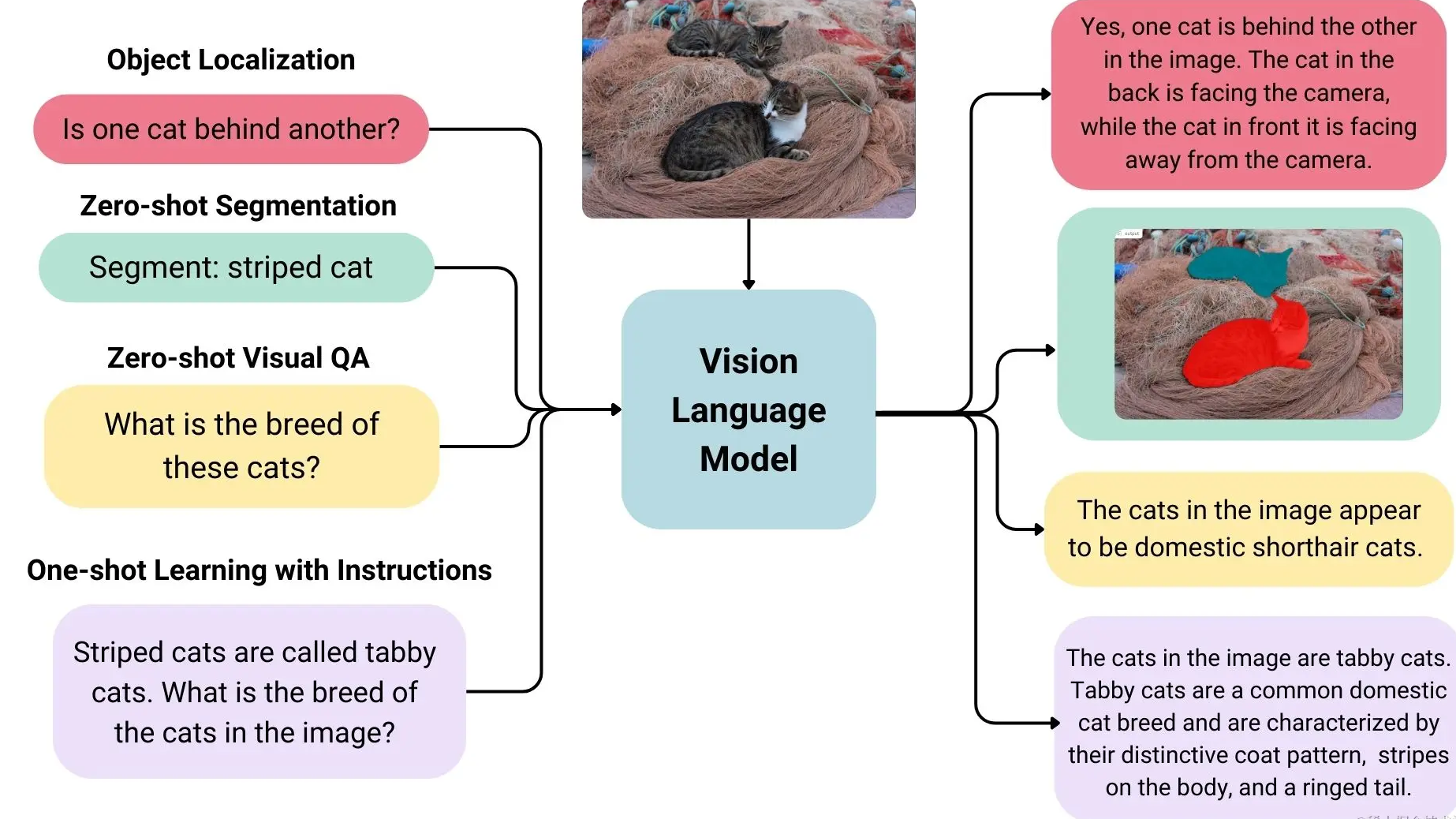
Overview of open source visual language models
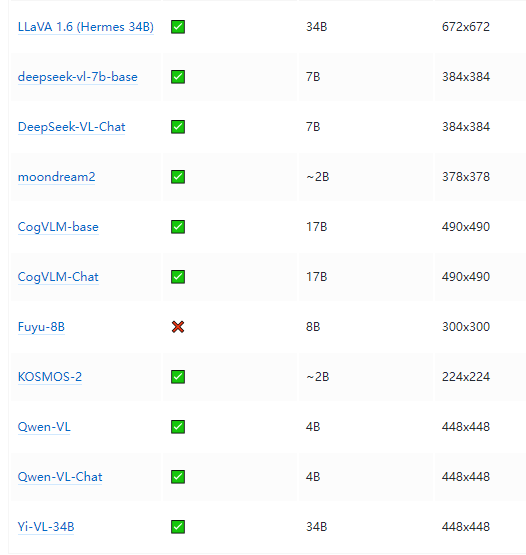
There are many open visual language models available on Hugging Face Hub, some of the best ones are listed in the table below.
There are basic models and models fine-tuned for chat that can be used in conversation scenarios.
Some of these models have a “grounding” feature that reduces model illusion.
Unless otherwise stated, all models are trained in English.
Find the right visual language model
There are several ways to help you choose the model that’s best for you.
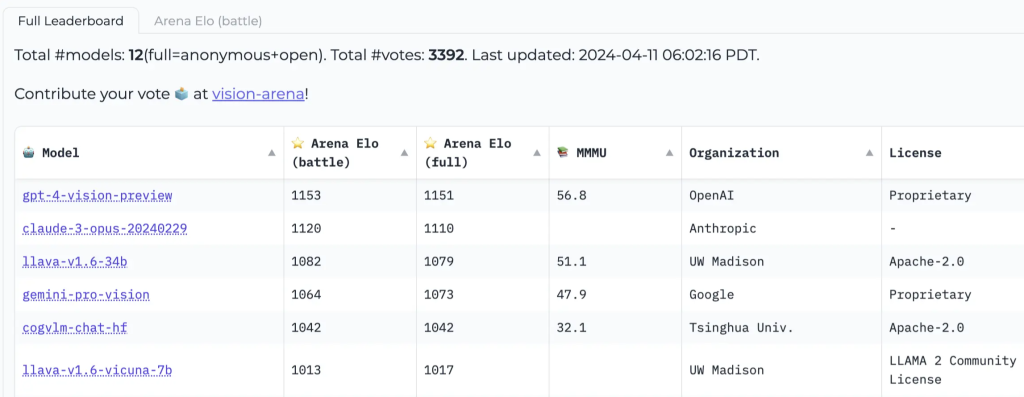
Vision Arena is an anonymous voting ranking based entirely on model output, and its rankings are constantly refreshed. In this arena, users input images and prompts, two anonymously different models generate outputs for them, and the user can then choose an output based on their preferences. The rankings generated this way are entirely based on human preferences.
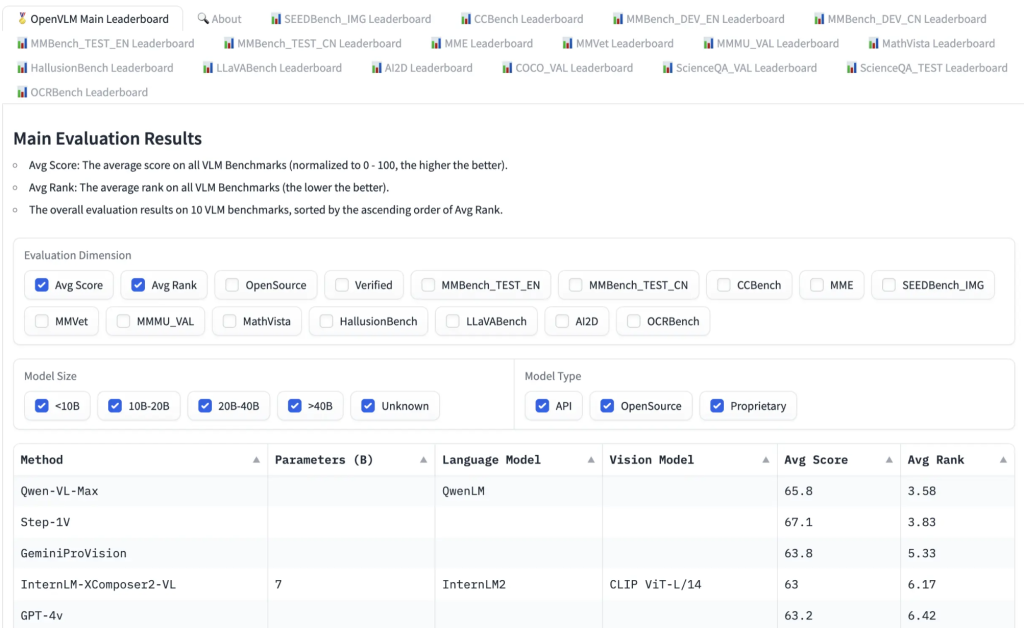
The Open VLM Ranking provides an alternative, where various visual language models are ranked according to the average score across all metrics. You can also filter models by model size, private or open source license, and rank them by metrics of your choice.
VLMEvalKit is a toolkit for running benchmarks on visual language models, on which the Open VLM leaderboard is based.
MMMU
A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI (MMMU) is the most comprehensive benchmark for evaluating visual language models. It contains 11.5K multimodal questions that require college-level subject knowledge as well as interdisciplinary (such as art and engineering) reasoning skills.
MMBench
MMBench consists of 3,000 multiple-choice questions covering over 20 different skills, including OCR, targeting, and more. The paper also introduces an evaluation strategy called CircularEval, which performs different combinations and shuffles of question options in each round, and expects the model to give the correct answer in each round.
In addition, there are other more targeted benchmarks for different application fields, such as MathVista (visual mathematical reasoning), AI2D (graph understanding), ScienceQA (scientific question answering) and OCRBench (document understanding).