

Lindb : A high-performance time-series database tailored for the big data era, making massive data storage and real-time analysis within reach. -Selected true open source to release new value.

Overview
Lindb is an open source distributed time series database that shows unique advantages in massive data storage and fast query computing with its high performance and scalability. The application of Lindb in Ele.me’s internal system has proven its reliability. It successfully stores all the company’s monitoring data and is able to process incremental data in TB units every day, with the cumulative data volume reaching the PB level.
Lindb’s design philosophy is about simplicity, not only in its use but also in its maintainability. It relies only on ETCD, a lightweight binary, which allows users to easily run Lindb in a stand-alone or distributed environment. In addition, Lindb supports a distributed cluster architecture, which provides it with excellent horizontal scalability, allowing it to adapt to growing data volumes and query needs.
In terms of high availability of data, Lindb supports a multi-copy mechanism, ensuring that even in extreme circumstances, such as only one copy remaining, the database can still provide services to the outside world. It also supports operations across multiple data centers (IDCs), allowing data writing in a single computer room, while enabling data aggregation queries in multiple computer rooms, which enhances the flexibility and efficiency of data processing.
Lindb adopts an eventual consistency model, which is a natural choice when pursuing low latency and scalability. It also has certain self-monitoring functions, can quickly respond to failover (FailOver), and certain self-governance capabilities, which can effectively defend against attacks by malicious users.
Overall, Lindb is a time series database designed for modern big data environments. It provides users with a powerful data storage and query solution through its simplicity, efficiency, and reliability.
Overall structure
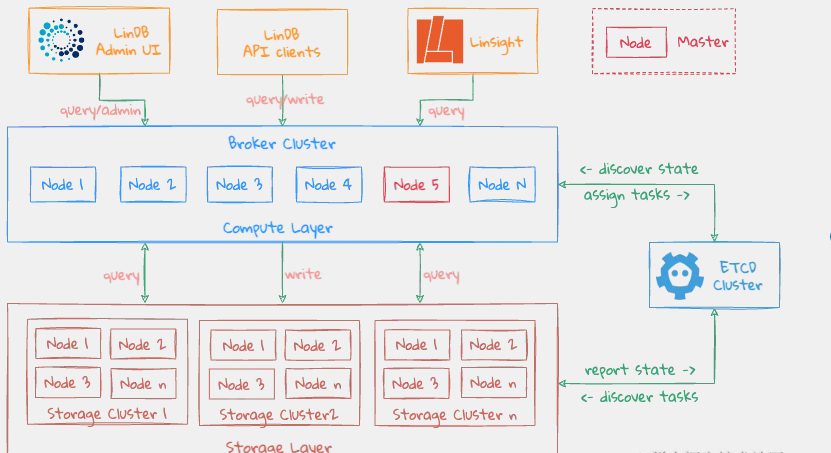
LinDB is an exquisitely designed distributed time series database. The core of its architecture lies in the efficient separation of computing and storage. It aims to achieve high availability and scalability of data processing through three core modules – Broker, Storage, and ETCD. This architectural design not only optimizes resource utilization, but also ensures the flexibility and stability of the system.
Computing layer (Broker Cluster) : As a stateless service, Broker plays the role of traffic entrance and query processing center. It uses a load balancing mechanism to evenly distribute requests, ensuring that write operations can be efficiently distributed to the Shard Leader of Storage based on Shard status, achieving reliable data writing and multi-copy backup. In the query scenario, Broker is responsible for generating and executing distributed query plans, summarizing query results from different storage nodes, supporting cross-machine room data aggregation, and demonstrating powerful computing and integration capabilities. In addition, the Master node in the Broker cluster is elected through preemptive election and is responsible for the centralized management and consistency maintenance of Metadata, simplifying the system architecture and ensuring the efficient execution of metadata operations.
Storage layer (Storage Cluster) : The Storage layer carries actual data storage and basic computing functions and is the stateful part of the system. Each Storage node focuses on the persistent storage of data and indexes, and directly handles data filtering, basic aggregation operations, Down Sampling and other operations, improving data reading efficiency. This layer responds to the Broker’s instructions to perform DDL operations, reflecting good collaborative working capabilities. Despite relying on external Metadata management, the Storage cluster maintains a high degree of horizontal scalability, ensuring scalability of data storage and access.
Metainformation management layer (ETCD) : As the cornerstone of LinDB’s metadata storage and distributed coordination, ETCD maintains all metadata and cluster status information of the system. Through ETCD, the system achieves unified scheduling and efficient propagation of Metadata changes, ensuring consistency across nodes. It is worth noting that LinDB has designed a mechanism to deal with ETCD failures. Without changing the existing Metadata, it uses metadata copies in the node memory to maintain services, demonstrating the system’s resilience and self-healing capabilities. When ETCD completely fails, the system has the ability to migrate metadata and status information to the new ETCD cluster, thereby achieving fault recovery and business continuity.
To sum up, LinDB achieves the decoupling of computing and storage through a carefully designed three-layer architecture, uses ETCD to strengthen metadata management, and ensures high performance and high reliability in large-scale time series data processing scenarios.
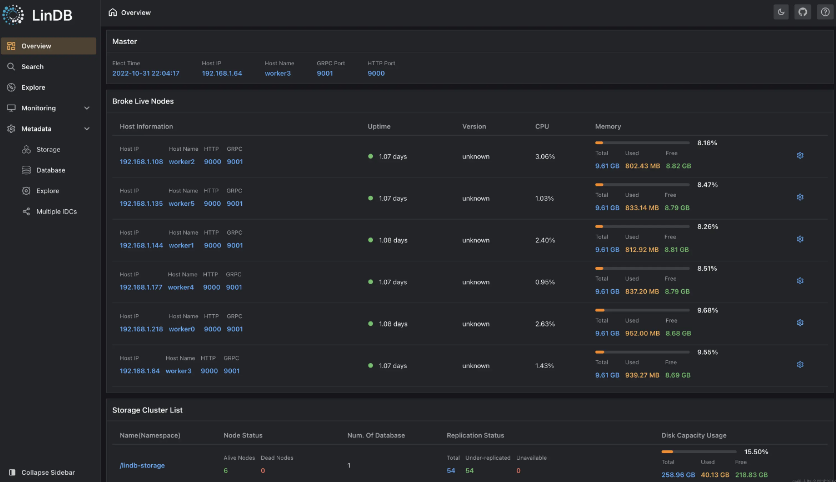
Management interface preview
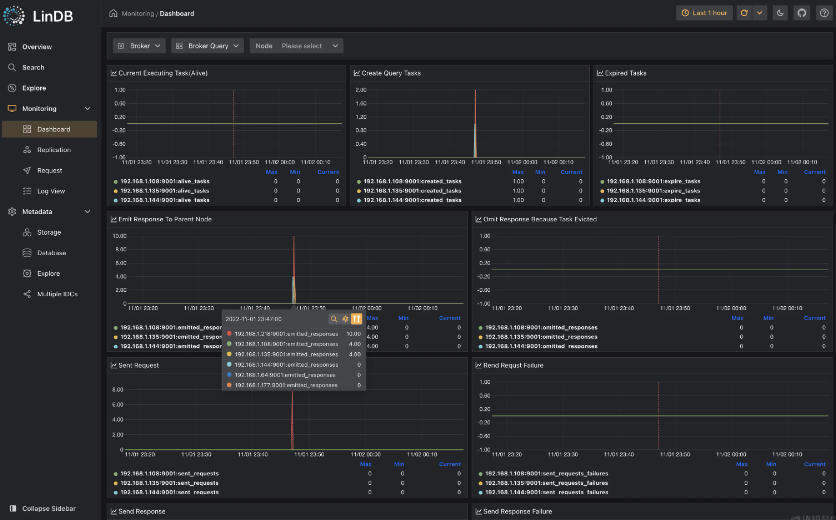
- Monitoring dashboard
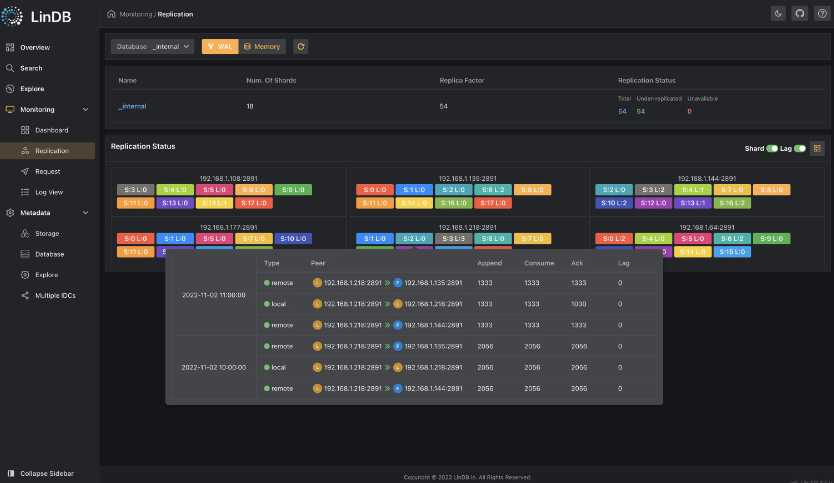
- copy status
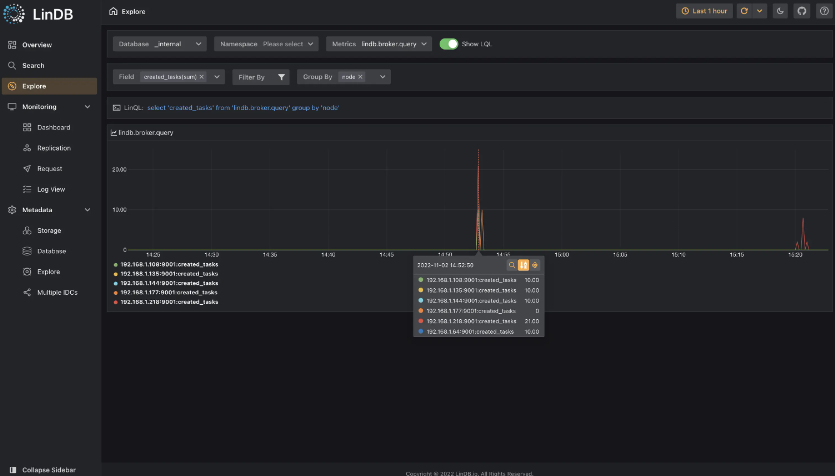
- Data exploration
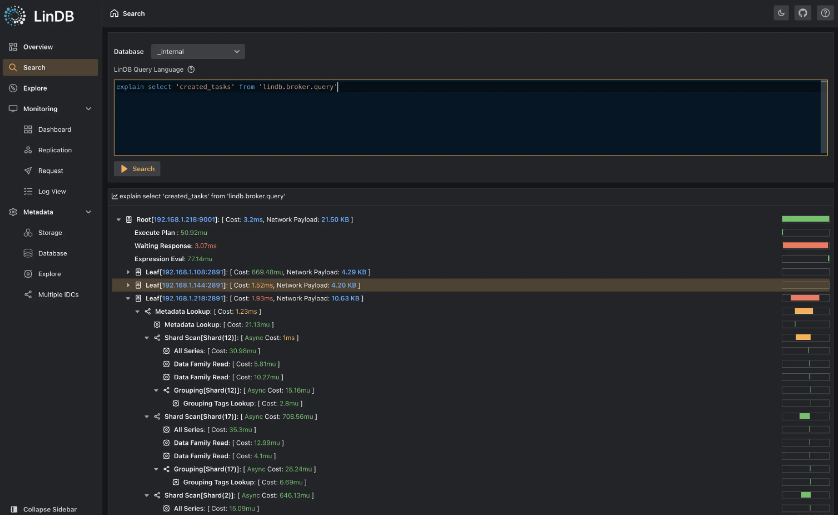
- SQL explanation
information
The overview as of press time is as follows:
- Software address : github.com/lindb/lindb
- Software protocol : Apache 2.0
- programming language :
| language | Proportion |
|---|---|
| Go | 86.2% |
| TypeScript | 12.5% |
| ANTLR | 0.5% |
| SCSS | 0.5% |
| Makefile | 0.1% |
| Shell | 0.1% |
| Other | 0.1% |
- Number of collections : 2.8K
Lindb, as an open source distributed time series database, has outstanding performance in large-scale data storage and fast query with its efficient performance and simple operation and maintenance. It relies on ETCD to achieve stand-alone or distributed operation, supports distributed clusters and multiple copies, and ensures high data availability. At the same time, Lindb’s cross-data center operation and eventual consistency model enhance its data processing capabilities. Nonetheless, Lindb may face challenges in data consistency, failure recovery, security, and performance optimization. Potential solutions include improving data synchronization, enhancing failover strategies, regularly updating security patches, and leveraging AI technology for performance tuning.