
Large model application development, must-see advanced RAG skills
Hello everyone, my name is Yufei. I have been exploring RAG-related technologies recently and analyzed the implementation of langchain and llamaindex-related technologies. Now I will summarize and share some of my experiences.
RAG cutting-edge progress
We use the screenshots in the paper below to illustrate the current progress of RAG technology.
Retrieval-Augmented Generation for Large Language Models: A Survey
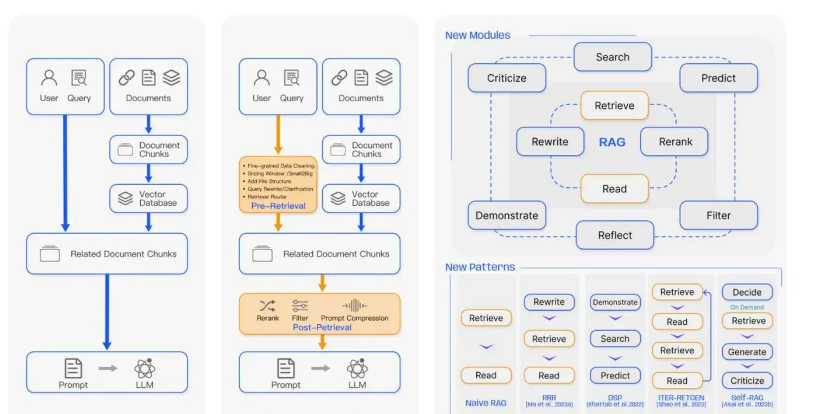
In addition to making fuss about the user’s input query, there are more operations for post-processing , such as multi-channel recall and reordering. And the latest technology has also added many new modules, such as self-RAG. This article introduces self-ness, by training a new LLM to adaptively retrieve paragraphs on demand, and generate and reflect the retrieved paragraphs and itself. The generated result. However, the process of this method is too long, and whether it is suitable for the actual online environment requires verification in real scenarios.
From the implementation of langchain and llama, as well as the content mentioned in the paper, the high-level technology of RAG shared this time is divided into three major modules.
One is Query Transformation , which is related to user query operations.
The second is Agent technology, which essentially uses the ability of large models to call functions to achieve more complex functions.
The third is Post-process , which is post-processing. After we retrieve the context, we can use some post-processing methods to process the data in order to obtain better context information.
Techniques such as reordering and multi-channel recall are relatively common, so I won’t elaborate on them too much.
Query Transformation
Query transformation mainly uses various techniques and large model capabilities to rewrite and convert the user’s query to enrich the semantic information of the query.
Query Rewrite
Because the original query may not always be optimal for LLM retrieval, especially in the real world, we first prompt LLM to rewrite the query and then perform retrieval-enhanced reading. This technology can refer to the example in langchain below. In essence, the prompt word project is used to write rewritten prompt words. This part of the prompt words can also be optimized.
template = """Provide a better search query for \
web search engine to answer the given question, end \
the queries with ’**’. Question: \
{x} Answer:"""
rewrite_prompt = ChatPromptTemplate.from_template(template)
def _parse(text):
return text.strip("**")
distracted_query = "man that sam bankman fried trial was crazy! what is langchain?"
rewriter = rewrite_prompt | ChatOpenAI(temperature=0) | StrOutputParser() | _parse
rewriter.invoke({"x": distracted_query})
MultiQuery
It is essentially an improved version of query rewrite. It can generate n queries similar to the user query at the same time and then retrieve them at the same time. This ensures that the recalled content matches the original query as much as possible. For details, please refer to the code below, which requires the latest version of langchian.
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_openai import ChatOpenAI
question = "What are the approaches to Task Decomposition?"
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectordb.as_retriever(), llm=llm
)
Hyde
The full name of Hyde is Hypothetical Document Embeddings . It uses LLM to generate a hypothetical document based on the user’s query, and then finds N similar vectors based on the vector of this document. The core principle is that the generated hypothetical document is closer to the embedding space than the query.
With the iteration of versions, the description of hyde in langchain’s documentation has changed somewhat. From the source code, we can see that there are a variety of built-in prompt word templates.
PROMPT_MAP = {
"web_search": web_search,
"sci_fact": sci_fact,
"arguana": arguana,
"trec_covid": trec_covid,
"fiqa": fiqa,
"dbpedia_entity": dbpedia_entity,
"trec_news": trec_news,
"mr_tydi": mr_tydi,
}
You can refer to the implementation of the code below.
from langchain_openai import OpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.chains import LLMChain, HypotheticalDocumentEmbedder
from langchain.prompts import PromptTemplate
base_embeddings = OpenAIEmbeddings()
llm = OpenAI()
embeddings = HypotheticalDocumentEmbedder.from_llm(llm, base_embeddings, "web_search")
result = embeddings.embed_query("Where is the Taj Mahal?")
Step-Back Prompt
Let the large model answer by first answering a step-back question and then putting the retrieved answer to that question together with the information retrieved from the user’s QA pair.
The idea of this prompt word is that if a question is difficult to answer, you can first ask a question that can help answer the question, but is coarser and simpler. The following figure is the implementation idea and introduction of Step-Back’s prompt word.
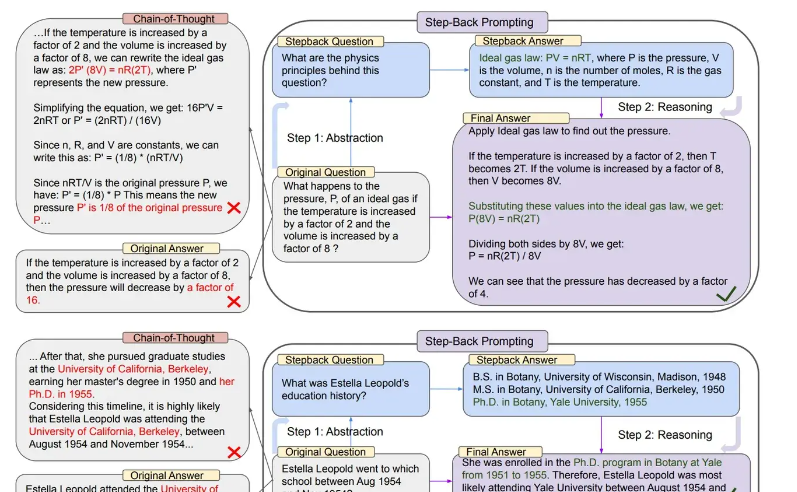
You can refer to the following code for the core prompt words.
You are an expert of world knowledge. I am going to ask you a question.
Your response should be comprehensive and not contradicted with the following context if they are relevant.
Otherwise, ignore them if they are not relevant.\n
\n{normal_context}\n
{step_back_context}\n
\nOriginal Question: {question}\n
Answer:
The prompt words of Step-back can be implemented and optimized by referring to the following paragraph.
You are an expert at world knowledge.
Your task is to step back and paraphrase a question to a more generic step-back question, which is easier to answer.
Here are a few examples:
Agent
The core is to use the function call function and prompt word project of the large model to execute some strategies, such as automatically selecting the data source that needs to be retrieved when there are multiple data sources.
Router
When there are multiple data sources, use routing technology to locate the query to the specified data source. You can refer to the implementation of llamaindex, which is relatively simple and clear.
from llama_index.tools.types import ToolMetadata
from llama_index.selectors.llm_selectors import (
LLMSingleSelector,
LLMMultiSelector,
)
tool_choices = [
ToolMetadata(
name="covid_nyt",
description=("This tool contains a NYT news article about COVID-19"),
),
ToolMetadata(
name="covid_wiki",
description=("This tool contains the Wikipedia page about COVID-19"),
),
ToolMetadata(
name="covid_tesla",
description=("This tool contains the Wikipedia page about apples"),
),
]
selector_result = selector.select(
tool_choices, query="Tell me more about COVID-19"
)
Post-Process
It mainly optimizes the context after user retrieval. Here are some commonly used ones.
Long-text Reorder
According to the paper Lost in the Middle: How Language Models Use Long Contexts, experiments show that large models are easier to remember documents at the beginning and end, but have less ability to remember documents in the middle part. Therefore, they can be based on the correlation between the recalled documents and the query. Sexual reordering.
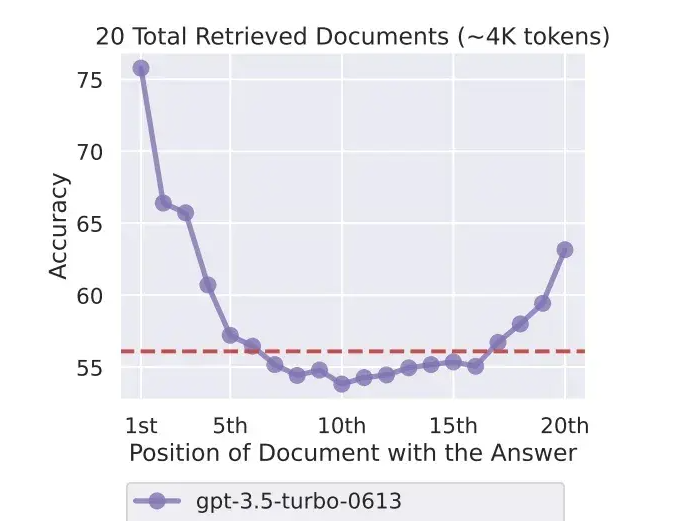
The core code can refer to the implementation of langchain:
def _litm_reordering(documents: List[Document]) -> List[Document]:
"""Lost in the middle reorder: the less relevant documents will be at the
middle of the list and more relevant elements at beginning / end.
See: https://arxiv.org/abs//2307.03172"""
documents.reverse()
reordered_result = []
for i, value in enumerate(documents):
if i % 2 == 1:
reordered_result.append(value)
else:
reordered_result.insert(0, value)
return reordered_result
Contextual compression
Essentially, LLM is used to determine the correlation between the retrieved documents and the user query, and only the k documents with the highest correlation are returned.
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain_openai import OpenAI
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.get_relevant_documents(
"What did the president say about Ketanji Jackson Brown"
)
print(compressed_docs)
Refine
The answers generated by the final large model are further rewritten to ensure the accuracy of the answers. It mainly involves the prompt word project. The reference prompt words are as follows:
The original query is as follows: {query_str}
We have provided an existing answer: {existing_answer}
We have the opportunity to refine the existing answer (only if needed) with some more context below.
------------
{context_msg}
------------
Given the new context, refine the original answer to better answer the query. If the context isn't useful, return the original answer.
Refined Answer:
Emotion Prompt
It is also part of the prompt word project, and the idea comes from Microsoft’s paper:
Large Language Models Understand and Can Be Enhanced by Emotional Stimuli
In the paper, Microsoft researchers proposed that adding some emotion-related cues to the prompt words would help large models output high-quality answers.
The reference words are as follows:
emotion_stimuli_dict = {
"ep01": "Write your answer and give me a confidence score between 0-1 for your answer. ",
"ep02": "This is very important to my career. ",
"ep03": "You'd better be sure.",
# add more from the paper here!!
}
# NOTE: ep06 is the combination of ep01, ep02, ep03
emotion_stimuli_dict["ep06"] = (
emotion_stimuli_dict["ep01"]
+ emotion_stimuli_dict["ep02"]
+ emotion_stimuli_dict["ep03"]
)
from llama_index.prompts import PromptTemplate
qa_tmpl_str = """\
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge, \
answer the query.
{emotion_str}
Query: {query_str}
Answer: \
"""
qa_tmpl = PromptTemplate(qa_tmpl_str)
postscript
RAG technology has been a key development technology for 24 years. Optimization technologies and methods are emerging in endlessly, and the best one is suitable for your business. This article will be gradually updated with the latest research and technology. If you are interested, you can like and collect it.
Finally, I would like to talk about some of my own insights and thoughts after participating in some forums. Welcome to exchange and learn together.
• The functions of the open source community can reach the level of 70 points, and some companies require at least 90 points before they can be used.
• Recall is important, but sometimes precision is more important
• Develop an evaluation system suitable for this scenario, end-to-end and sub-module evaluation
• There is no one-size-fits-all solution