
Welcome back to the “Mastering RAG” series! Let’s roll up our sleeves and dive into the complex world of building an enterprise-grade RAG system.
While the Internet is filled with articles about simple RAG systems, the process of building a robust enterprise-wide solution is often filled with unknowns. Most builders don’t even know what their most important decisions are when building a RAG system…
But this blog isn’t just a theoretical journey, it’s also a practical guide to help you take action! From the importance of safeguards to ensuring security to the impact of query rewriting on user experience, we’ll provide actionable insights and real-world examples. Whether you’re an experienced developer or a technical leader leading a team, buckle up and get ready to delve into the complex world of cutting-edge, enterprise-grade RAG!
Before discussing RAG architecture, I’d like to share some recent research on common failure points when building RAG systems. Researchers analyzed case studies from three unique domains and discovered seven common RAG failure points.
Challenges in building a RAG system
case study:
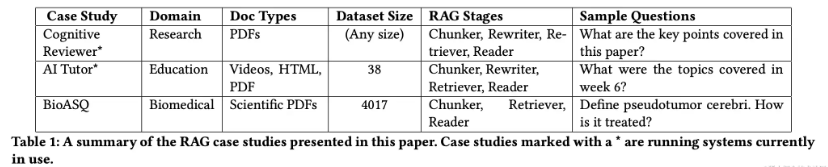
Cognitive reviewer
Cognitive Reviewer is a RAG system designed to help researchers analyze scientific literature. Researchers can define a research question or goal and then upload a series of related research papers. All documents are then sorted according to the stated objectives for manual review by researchers. Additionally, researchers can ask questions directly to the entire document collection.
Artificial Intelligence Tutor (AI Tutor)
AI Tutor is another RAG system that allows students to ask questions about a unit and get answers based on the learning content. Students can verify answers by accessing a list of sources. The AI tutor is integrated into Deakin University’s learning management system and can index all content, including PDFs, videos and text documents. The system uses the Whisper deep learning model to transcribe the video before segmenting it. The RAG pipeline includes a rewriter for query generalization, and the chat interface leverages past conversations to provide context for each question.
Biomedical Q&A
In the Biomedical Q&A case study, a RAG system was created using the BioASQ dataset, which contains questions, document links, and answers. Prepared by biomedical experts, this dataset contains domain-specific question-answer pairs. Answers to questions can be true or false, text summaries, factual statements, or lists.
7 points of failure in RAG systems
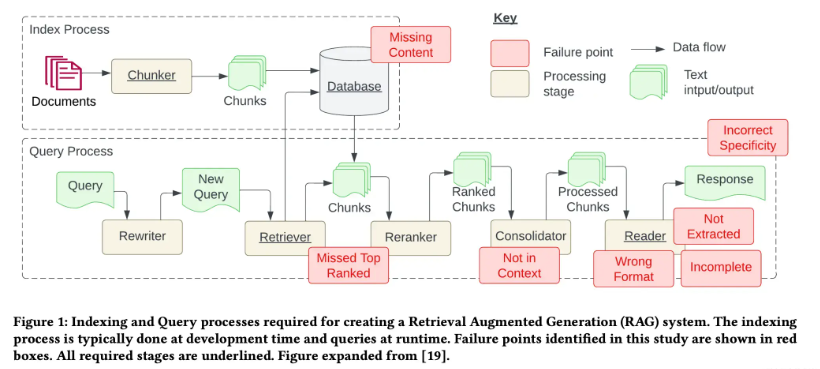
Through these case studies, the researchers identified seven common failure points when building RAG systems:
- Missing content (FP1) : Users asked questions that could not be answered with existing documentation. Ideally, the RAG system would reply with a message like “Sorry, I didn’t know.” However, responses to content-related questions that lack clear answers may be misleading.
- Missing Top Documents (FP2) : The answer to the question is present in the document, but is not ranked high enough to be included in the results returned to the user. Although in theory all documents are ranked and used in subsequent steps, in practice only the top K documents are returned, with the K value chosen based on performance.
- Out of Context – Integration Policy Limitation (FP3) : The document containing the answer was retrieved from the database but failed to be integrated into the context in which the reply was generated. This happens when a large number of documents are returned, causing the integration process to be blocked, thereby preventing the retrieval of relevant answers.
- Not Extracted (FP4) : The answer is present in the context, but the model failed to extract the correct information. This usually occurs when there is a lot of noise or conflicting information in the context.
- Format Error (FP5) : The problem involves extracting information in a specific format, such as a table or list, but the model ignores the instruction.
- Specificity error (FP6) : The reply contains the answer, but lacks the necessary specificity or is overly specific and fails to meet the user’s needs. This occurs when the RAG system designer presupposes an outcome for a given problem, such as a teacher seeking educational content. In this case, specific educational content should be provided in addition to the answers. Specificity errors also occur when users are unsure how to word a question that is too general.
- Incomplete (FP7) : An incomplete answer, while accurate, is missing some information, even if the information is present in the context and can be extracted. For example, a question like “What key points are covered in documents A, B, and C?” would be better if they were asked separately.
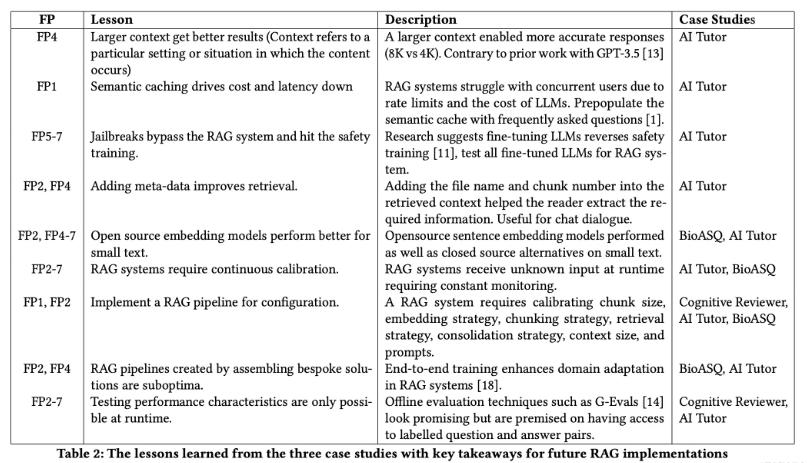
The table below summarizes the lessons they learned solving each problem. We will keep these lessons in mind when building enterprise-grade RAG systems.
How to build an enterprise-level RAG system
Now that we understand the common problems encountered when designing a RAG system, we will step through the design requirements and role of each component, as well as the best practices for building these components. The RAG system architecture diagram above provides context for where and how each component is used.
User Authentication
This is the starting point of the entire system! Before a user can start interacting with a chatbot, we need to authenticate the user for various reasons. Authentication helps ensure security and personalization, which is essential for enterprise systems.
- Access Control : Authentication ensures that only authorized users can access the system. It helps control who can interact with the system and what actions they are allowed to perform.
- Data security : Protecting sensitive data is critical. User authentication prevents unauthorized individuals from accessing confidential information, thereby preventing data breaches and unauthorized data manipulation.
- User Privacy : Authentication helps maintain user privacy by ensuring that only intended users have access to their personal information and account details. This is critical to building user trust.
- Legal Compliance : Many jurisdictions and industries have regulations and laws requiring organizations to implement appropriate user authentication to protect user data and privacy. Complying with these regulations can help avoid legal issues and potential penalties.
- Accountability : Authentication ensures accountability by linking actions within the system to specific user accounts. This is essential for auditing and tracking user activity, helping to identify and resolve any security incidents or suspicious behavior.
- Personalization and customization : Authentication allows the system to identify individual users, allowing for personalization and customization of the user experience. This can include customized content, preferences and settings.
Services like AWS Cognito or Firebase Authentication can help you easily add user registration and authentication to mobile and web applications.
Enter guardrail
Preventing user input that is harmful or contains private information is critical. Recent research shows how easy it is to hijack large language models (LLMs). This is where input guardrails come into play. Let’s look at different scenarios where guardrails are needed.
- Anonymize : Input guardrails can anonymize or redact personally identifiable information (PII) such as name, address, or contact details. This helps protect privacy and prevent malicious attempts to disclose sensitive information.
- Restrict substrings : Prevent security vulnerabilities or unwanted behavior by prohibiting certain substrings or patterns that could be exploited for SQL injection, cross-site scripting (XSS), or other injection attacks.
- Restrict topics : In order to limit discussion or input related to specific topics that may be inappropriate, offensive, or violate the Community Guidelines, it is important to filter out content that contains hate speech, discrimination, or pornographic content.
- Restrict code : Injection of executable code must be prevented, which could compromise system security or lead to code injection attacks.
- Restrict languages : Verify that text input is in the correct language or script to prevent potential misunderstandings or errors during processing.
- Detecting hint injection : Mitigating attempts to inject misleading or harmful hints that could manipulate the system in unintended ways or affect the behavior of large language models.
- Limit tokens : Enforcing maximum token or character limits on user input can help avoid resource exhaustion and prevent denial of service (DoS) attacks.
- Detect toxicity : Implement a toxicity filter to identify and block input containing harmful or abusive language.
To protect your RAG system from these scenarios, you can take advantage of Llama Guard provided by Meta. You can host it yourself or use a hosting service like Sagemaker. However, don’t expect it to detect toxic content perfectly.
query rewriter
Once the query passes the input guardrails, we send it to the query rewriter. Sometimes, user queries can be ambiguous or require context to better understand the user’s intent. Query rewriting is a technique that helps solve this problem. It involves transforming user queries to improve clarity, accuracy and relevance. Let’s take a look at some of the most commonly used techniques:
- History-based rewriting : In this approach, the system leverages the user’s query history to understand the context of the conversation and improve subsequent queries. For example, credit card query:
Query history:
- How many credit cards do you have?
- Are there annual fees for Platinum and Gold Cards?
- Compare the features of both.
Based on user query history, we need to identify the development of context, discern the intent and correlation between user queries, and generate queries that are consistent with the evolving context.
Rewritten query: Compare features of Platinum and Gold cards.
- Create subqueries : Complex queries can be difficult to answer due to retrieval issues. To simplify the task, the query is broken down into more specific subqueries. This helps retrieve the correct context needed to generate the answer. LlamaIndex calls this a subquestion query engine.
For example, for the query “Compare features of Platinum and Gold cards,” a subquery is generated for each credit card that focuses on the individual entities mentioned in the original query.
Rewritten subquery:
- What are the functions of Platinum Credit Card?
- What are the functions of gold credit card?
- Create similar queries : To increase the likelihood of retrieving relevant documents, we generate similar queries based on user input. This can overcome limitations of retrieval in terms of semantic or lexical matching.
If a user asks about the features of a credit card, the system generates related queries. You can use synonyms, related terms, or domain knowledge to create queries that match the user’s intent.
Similar queries generated:
- I want to know about the platinum credit card. -> Tell me about the advantages of Platinum Credit Card.
Factors to consider when choosing a text encoder
When choosing a text encoder, you need to decide whether to use a private or public encoder. You may be inclined to use private encoders due to their ease of use, but there are some specific pros and cons to weigh between the two options. This is an important decision that will affect your system’s performance and latency.
- Query costEnsuring a smooth user experience for semantic search relies on the high availability of embedded API services. OpenAI and similar vendors provide reliable APIs that eliminate the need for managed administration. However, choosing an open source model requires an engineering investment based on model size and latency needs. Smaller models (up to 110 million parameters) can take advantage of CPU instance hosting, while larger models may require GPU services to meet latency requirements.
- Indexing costSetting up semantic search involves indexing documents, which incurs non-trivial costs. Because indexes and queries share the same encoder, indexing costs depend on the encoder service chosen. To facilitate service reset or re-indexing into an alternative vector database, it is recommended to store embedding vectors separately. Omitting this step will require recomputing the same embedding vectors.
- storage costFor applications that index millions of vectors, the storage cost of the vector database is an important factor. Storage cost scales linearly with dimensions, and OpenAI’s embedding vector in 1526 dimensions generates the largest storage cost. To estimate storage costs, calculate the average unit (phrase or sentence) per document and extrapolate.
- language supportTo support your non-English languages, you can use a multilingual encoder or combine a translation system with an English encoder.
- search delayThe latency of semantic search grows linearly with the dimensionality of the embedding vector. To minimize latency, it is better to choose lower dimensional embedding vectors.
- privacyStrict data privacy requirements in sensitive areas like finance and healthcare may make services like OpenAI unfeasible.
Document ingestion
The document ingestion system manages the processing and persistence of data. During the indexing process, each document is divided into smaller chunks and then converted into embedding vectors using an embedding model. The original blocks and embedding vectors are then indexed together into the index database. Let’s look at the components of a document ingestion system.
- Document parserDocument parsers play a central role in proactively extracting structured information from various document formats, with a particular focus on format processing. This includes, but is not limited to, parsing PDF documents that may contain images and tables.
- Document formatThe document parser must be able to handle various document formats proficiently, such as PDF, Word, Excel, etc., to ensure the adaptability of document processing. This involves identifying and managing embedded content, such as hyperlinks, multimedia elements, or annotations, to provide a comprehensive representation of the document.
- Table identificationIdentifying and extracting tabular data from documents is crucial to maintaining the structure of information, especially in reports or research papers. Extracting table-related metadata, including header, row, and column information, can enhance understanding of the document’s organizational structure. Models such as Table Converter can be used for this task.
- Image IdentificationOptical character recognition (OCR) is applied to images in documents to proactively identify and extract text, making it ready for indexing and subsequent retrieval.
- Metadata extractionMetadata refers to additional information about a document that is not part of the main content of the document. It includes details such as author, creation date, document type, keywords, etc. Metadata provides valuable context and helps organize documents, and improves the relevance of search results by taking into account metadata attributes. Metadata can be extracted using NLP/OCR pipelines and indexed with the document as special fields.
- ChunkerHow you decide to tokenize (split) long text can determine embedding vector quality and the performance of your search system. If the chunks are too small, some questions cannot be answered; if the chunks are too long, the answers contain generated noise. You can leverage summarization techniques to reduce noise, text size, encoding costs, and storage costs.Chunking is an important but often underestimated topic. It may require domain expertise similar to feature engineering. For example, chunking of a Python code base might be done using prefixes such as def/class. For a more in-depth look at chunking, read our blog post.

Indexer
As the name suggests, an indexer is responsible for creating an index of documents, which serves as a structured data structure (say that three times quickly…). Indexers facilitate efficient search and retrieval operations. An efficient index is essential for retrieving documents quickly and accurately. It involves mapping blocks or tokens to their corresponding positions in a collection of documents. Indexers perform important tasks in document retrieval, including creating indexes and adding, updating, or deleting documents.
As a key component of the RAG system, the indexer faces various challenges and problems, which will affect the overall efficiency and performance of the system.
- Scalability issues
As document volume grows, maintaining an efficient and fast index becomes challenging. Scalability issues can arise when a system struggles to handle an increasing number of documents, resulting in slower indexing and retrieval speeds.
- Real-time index updates
In systems where documents are frequently added, updated, or deleted, keeping the index updated in real time can be challenging. Ensuring that real-time APIs and real-time indexing mechanisms operate seamlessly without impacting system performance is an ongoing challenge.
- Consistency and atomicity
Achieving consistency and atomicity can be complex when faced with concurrent document updates or modifications. Ensuring that index updates maintain data integrity even in the presence of concurrent changes requires careful design and implementation.
- Optimize storage space
Indexing a large number of documents can result in significant storage requirements. Optimizing storage space while ensuring indexes remain accessible and responsive is an ongoing challenge, especially as storage costs become a concern.
- Security and access control
It is critical to implement appropriate security measures and access controls to prevent unauthorized modifications to the index. Ensuring that only authorized users or processes can perform CRUD operations helps protect the integrity of the document repository.
- Monitor and maintain
Regularly monitoring the health and performance of your indexers is critical. Detecting issues such as index failures, resource bottlenecks, or outdated indexes requires robust monitoring and maintenance procedures to ensure the system runs smoothly over time.
These are some well-known software engineering challenges that can be solved by following good software design practices.
data storage
Since we deal with a variety of data, we need dedicated storage for each type of data. For each storage type and its specific use case, it’s important to understand the different considerations.
- embedding vector
- Database type: SQL/NoSQL Storing document embedding vectors individually enables fast re-indexing without having to recompute embedding vectors for the entire document corpus. Additionally, embedded vector storage acts as a backup, ensuring the retention of critical information even in the event of a system failure or update.
- document
- Database type: NoSQL Storing documents in their original format is essential for persistent storage. This raw format serves as the basis for various processing stages such as indexing, parsing, and retrieval. It also provides flexibility for future system enhancements, as the original document remains intact and can be reprocessed as needed.
- Chat history
- Database type: NoSQL Storing chat history is essential to support the conversational aspect of the RAG system. Chat history storage allows the system to recall a user’s previous queries, responses, and preferences, allowing it to adapt and tailor future interactions to the user’s unique context. These historical data are an important resource for improving machine learning systems by leveraging them for research.
- customer feedback
- Database type: NoSQL/SQL User feedback is systematically collected through various interaction mechanisms in RAG applications. In most LLM systems, users can provide feedback using likes/dislikes, star ratings, and text feedback. This set of user insights serves as a valuable repository of user experience and perception and forms the basis for continuous system enhancement.
- vector database
The vector database that provides support for semantic search is the key retrieval component of the RAG system. However, choosing the right components is critical to avoiding potential problems. There are several vector database factors to consider during the selection process. Let’s take a look at some of them.
- Recall vs. Latency In vector databases, there is a trade-off between optimizing recall (the percentage of relevant results) and latency (the time it takes to return results). Different indexes such as Flat, HNSW (Hierarchical Navigable Small World), PQ (Product Quantification), ANNOY, and DiskANN make different trade-offs between speed and recall. Benchmark your data and queries to make informed decisions.
- Cost Cloud-native databases with hosted solutions are typically billed based on data storage and query volume. For organizations with large amounts of data, this model can avoid infrastructure costs. Key considerations include assessing data set growth, team capabilities, data sensitivity and understanding the cost impact of a hosted cloud solution.
- Self-Hosted vs. Managed Services On the other hand, self-hosted provides organizations with greater control over their infrastructure and may also cost less. However, it also comes with the responsibility of managing and maintaining the infrastructure, including scalability, security, and update considerations.
- Insertion Speed Versus Query Speed It is critical to balance insertion speed and query speed. Look for a vendor that can handle streaming use cases with high insertion speed requirements. However, for most organizations, prioritizing query speed is more relevant. Evaluate vector insertion speed query latency during peak hours to make informed decisions.
- In-memory vs. Disk Index Storage Choosing between in-memory storage and disk storage involves speed and cost trade-offs. While in-memory storage provides high-speed performance, some use cases require storing vectors larger than memory. Technologies such as memory mapped files can expand vector storage without affecting search speed. New indexes such as Vamana in DiskANN promise to provide efficient out-of-memory indexing.
Full-Text search vs. Vector Hybrid search
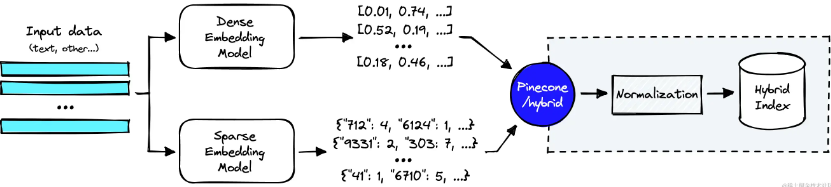
Source: www.pinecone.io/learn/hybri…
Vector search alone may not be sufficient for enterprise-level applications. On the other hand, hybrid searches, i.e. searches that integrate dense and sparse methods, require additional work. Implementing dense vector indexing, sparse inverted indexing, and reordering steps are typical. Adjust the balance between dense and sparse elements in Pinecone, Weaviate, and Elasticsearch via a parameter called alpha.
- filter
Real-world search queries often involve filtering on metadata attributes. While pre-filtered searches may seem natural, they can result in a lack of relevant results. Post-filter searches can be problematic if the attributes being filtered in the filtered search query represent only a small portion of the data set. Custom filtered searches like Weaviate combine pre-filtered and inverted index shards with efficient semantic search of HNSW index shards.
- Technology to improve search efficiency
Recent research shows that large language models (LLMs) are easily distracted by irrelevant context, and having a large amount of context (topK retrieved documents) may miss some context due to the attention patterns of LLMs. Therefore, it is crucial to leverage relevant and diverse documents to improve retrieval. Let’s look at some proven techniques for improving retrieval.
- Hypothetical Document Embedding (HyDE)
We can use HyDE technology to solve the problem of poor retrieval performance, especially when dealing with short queries or mismatched queries, which can make it difficult to find information. HyDE takes a unique approach to solving this problem by using hypothetical documents created using models such as GPT. These hypothetical documents capture important patterns but may have fictitious or incorrect details. An intelligent text encoder then converts this hypothetical document into a vector embedding. This embedding helps to find similar real documents in the collection better than the query’s embedding.
Experiments show that HyDE performs better than other advanced methods, making it a useful tool for improving the performance of RAG systems.
- Query route
Query routing brings advantages when working with multiple indexes, directing queries to the most relevant index for efficient retrieval. This approach streamlines the search process by ensuring that each query is directed to the appropriate index, optimizing the accuracy and speed of information retrieval.
In the context of enterprise search, where data comes from a variety of sources such as technical documentation, product documentation, tasks, and code repositories, query routing becomes a powerful tool. For example, if a user searches for information related to a specific product feature, the query can be intelligently routed to an index containing product documentation, thereby improving the accuracy of the search results.
- reranker
Rerankers are used to enhance document ranking when the results retrieved from the encoder do not provide the best quality. It has become common practice to utilize open source encoder-only transformers such as BGE-large for cross-encoder setups. Recent decoder-only methods, such as RankVicuna, RankGPT, and RankZephyr, further improve the performance of re-rankers.
Introducing a reranker has its benefits in reducing LLM hallucinations in responses and improving the cross-domain generalization of the system. However, it also has disadvantages. Complex rerankers may increase latency due to high computational overhead, impacting real-time applications. Additionally, deploying advanced rerankers can be resource intensive and requires careful consideration of the balance between performance improvements and resource utilization.
- Maximum Marginal Relevance (MMR)
MMR is a method designed to enhance the diversity of retrieved items in the response and avoid redundancy. Rather than focusing only on retrieving the most relevant items, MMR strikes a balance between relevance and diversity. It’s like introducing someone to a friend at a party. First, identify the best match based on your friend’s preferences. Then, look for someone a little different. This process continues until the required number of introductions is reached. MMR ensures a more diverse and relevant set of items is presented, minimizing redundancy.

- Automatic truncation
The automatic truncation feature in Weaviate is designed to limit the number of search results returned by detecting groups of objects with similar scores. It works by analyzing the scores of search results and identifying significant jumps in these values, which may indicate a transition from highly relevant to less relevant results.
For example, consider a search that returns objects with the following distance values:
[0.1899, 0.1901, 0.191, 0.21, 0.215, 0.23].
Automatic truncation returns the following results:
autocut: 1: [0.1899, 0.1901, 0.191]
autocut: 2: [0.1899, 0.1901, 0.191, 0.21, 0.215]
autocut: 3: [0.1899, 0.1901, 0.191, 0.21, 0.215, 0.23]

Source: youtu.be/TRjq7t2Ms5I…
Recursive retrieval, also known as small-to-large retrieval technology, embeds smaller chunks for retrieval while returning larger parent contexts to the language model for synthesis. Smaller chunks of text facilitate more accurate retrieval, while larger chunks provide richer contextual information to the language model. This continuous process optimizes retrieval accuracy by initially focusing on smaller, more information-dense units, and then efficiently linking them to broader contextual parent chunks for synthesis.
- Sentence window search
The retrieval process takes a single sentence and returns a window of text surrounding that specific sentence. Sentence window retrieval ensures that the information retrieved is not only accurate but also contextually relevant, providing comprehensive information around the main sentence.
- Builder
Now that we’ve discussed all the retrieval components, let’s talk about generators. This requires careful consideration and trade-offs, primarily between self-hosted inference deployments and private API services. This is a big topic in itself and I’ll mention it briefly to avoid overwhelming you.
- API considerations
When evaluating API servers for LLMs, it’s critical to prioritize features that ensure seamless integration and strong performance. A well-designed API should serve as a simple launcher for popular LLMs, while also addressing key considerations such as production readiness, security, and hallucination detection. Notably, HuggingFace’s TGI server embodies a comprehensive set of capabilities that embody these principles. Let’s take a look at some of the most popular features required in an LLM server.
- performance
An efficient API must prioritize performance to meet different user needs. Tensor parallelism is a feature that enables faster inference on multiple GPUs, enhancing overall processing speed. Additionally, continuous batching of incoming requests ensures an increase in overall throughput, helping to achieve a more responsive and scalable system. Quantization using bits and bytes and GPT-Q further optimizes the API, improving efficiency in a variety of use cases. Leveraging optimized transformer code ensures seamless inference on the most popular architectures.
- Build quality enhancer
To improve the quality of the build, the API should include functionality that can transform the output. The logarithmic processor includes temperature scaling, top-p, top-k, and repetition penalties, allowing the user to customize the output to their preference. Additionally, stop sequences provide control over generation, allowing users to manage and optimize the content generation process. Log probability is crucial for hallucination detection, acting as an additional layer of refinement to ensure that the generated output is consistent with the intended context and avoids misleading information.
- safety
API security is critical, especially when dealing with LLMs and enterprise use cases. Secure tensor weight loading is an important feature that helps secure model deployment by preventing unauthorized tampering of model parameters. Additionally, the inclusion of watermarking technology adds an extra layer of security, making tracking and accountability possible in the use of LLMs.
- user experience
In the world of user experience, markup flow is a key feature for enabling seamless interactions. Leveraging server-sent events (SSE) for tag streaming enhances the real-time responsiveness of the API, providing users with a smoother and more interactive experience. This ensures that users receive the generated content incrementally, improving the overall engagement and usability of LLM.
- self-hosted inference
Self-hosted inference involves deploying LLMs on servers provided by cloud service providers such as AWS, GCP, or Azure. The choice of server, such as TGI, Ray or FastAPI, is a critical decision that directly affects the performance and cost of the system. Considerations include computational efficiency, ease of deployment, and compatibility with the selected LLM.
Measuring LLM inference performance is critical, and rankings such as Anyscale’s LLMPerf rankings are critical. It ranks inference providers based on key performance metrics, including time to first token (TTFT), inter-token latency (ITL), and success rate. Load testing and correctness testing are crucial to evaluate the different features of the hosting model.
Among the new approaches, Predibase’s LoRAX efficiently delivers finely tuned LLMs in an innovative way. It solves the challenge of serving multiple fine-tuned models using shared GPU resources.
- Private API service
LLM API services provided by companies like OpenAI, Fireworks, Anyscale, Replicate, Mistral, Perplexity, and Together provide alternative deployment methods. Understanding their capabilities, pricing models, and LLM performance metrics is critical. For example, OpenAI’s token-based pricing model, which differentiates between input and output tokens, can greatly impact the overall cost of using an API. When comparing the cost of private API services versus self-hosted LLMs, factors such as GPU cost, utilization, and scalability must be considered. For some cases, rate limiting may be a limiting factor.
- Improved RAG prompting technology
There are many hinting techniques for improving RAG output. In part two of our RAG Mastery series, we dive into the top 5 most effective methods. Many of these new technologies surpass the performance of CoT (Chain of Thoughts). You can also combine them to minimize illusions.

- Output guard bar
Output guardbars function similarly to their input counterparts, but are specifically designed to detect problems in the generated output. It focuses on identifying hallucinations, competitor mentions, and issues that could lead to brand damage as part of the RAG assessment. The goal is to prevent the generation of inaccurate or ethically questionable information that may not be in line with the brand’s values. By actively monitoring and analyzing output, this guardrail ensures that the content generated remains factually accurate, ethical, and consistent with the brand’s guidelines.
Here’s an example of a reply that could harm your business’s brand, but would be blocked by appropriate output guardrails:

- customer feedback
Once the output is generated and provided, it can be very helpful to get positive or negative feedback from users. User feedback is important in improving the driving force of the RAG system; this is an ongoing process rather than a one-time effort. This includes not only regularly performing automated tasks such as re-indexing and experiment re-runs, but also systematically integrating user insights to achieve substantial system enhancements.
The most impactful lever in system improvement lies in proactively solving problems in the underlying data. The RAG system should include an iterative workflow for handling user feedback and driving continuous improvement.
- User interaction and feedback collection
Users interact with the RAG app and provide feedback using features such as 👍/👎 or star reviews. This diverse set of feedback mechanisms collectively serves as a valuable inventory of users’ experiences and perceptions of system performance.
- Problem identification and diagnostic checks
After gathering feedback, the team can conduct a comprehensive analysis to identify queries that may be performing poorly. This involves examining the retrieved resources and scrutinizing them to determine whether poor performance stems from retrieval, generation, or the underlying data source.
- Data improvement strategy
Once issues are identified, especially those rooted in the data itself, teams can strategically develop plans to improve data quality. This may involve correcting incomplete information or restructuring poorly organized content.
- Evaluation and Testing Protocol
After implementing data improvements, the system must undergo a rigorous evaluation of previously underperforming queries. Insights gained from these evaluations can be systematically integrated into test suites, ensuring continuous review and refinement based on real-world interactions.
By actively engaging users in this comprehensive feedback loop, the RAG system not only solves the problems identified through the automated process, but also leverages the richness of the user experience.
Observability
Building a RAG system is more than just putting the system into production. Even with robust safeguards and high-quality data for fine-tuning, models still require ongoing monitoring after they go into production. Generative AI applications require specific LLM observability in addition to standard metrics such as latency and cost to detect and correct problems such as hallucinations, out-of-domain queries, and link failures. Now let’s look at the pillars of LLM observability.
- Hint Analysis and Optimization uses real-time production data to identify hint-related issues and iterates through a powerful evaluation mechanism to identify and resolve issues such as hallucinations.
- Traceability for LLM Apps Capture LLM trace data from common frameworks like Langchain and LlamaIndex for debugging tips and steps.
- Information retrieval enhancements troubleshoot and evaluate RAG parameters to optimize the retrieval process critical to LLM performance.
- Alerts Get alerts if your system behaves differently than expected, such as increased errors, high latency, hallucinations, etc.
First and foremost, real-time monitoring is critical to observing the performance, behavior, and overall health of your application in a production environment. Keep an eye on SLA compliance and set alerts to address any deviations promptly. Efficiently track the costs involved in running LLM applications by analyzing usage patterns and resource consumption to help you with cost optimization.
Galileo’s LLM Studio provides LLM observability specifically designed to proactively alert and take immediate corrective action before users complain. Galileo’s safeguard metrics are designed to monitor the quality and safety of your models, covering fundamentals, uncertainty, authenticity, tone, toxicity, PII, and more. These metrics, previously used for evaluation and experimentation, can now be seamlessly integrated into the monitoring phase.
Additionally, you have the flexibility to register custom indicators to tailor the monitoring process to meet your specific needs. Leverage insights and alerts generated from monitoring data to understand potential issues, anomalies, or areas for improvement that require attention. This comprehensive approach ensures your LLM applications run efficiently and securely in real-world scenarios.
cache
For companies operating at scale, cost can be a barrier. Caching is a great way to save money in this situation. Caching involves storing prompts and their corresponding responses in a database for later retrieval. This strategic caching mechanism enables large language model applications to speed up and save response costs through three significant benefits:
- Enhanced production inference : Caching helps make inference faster and more cost-effective in production. By leveraging cached responses, certain queries can achieve near-zero latency, simplifying the user experience.
- Accelerates development cycle : During the development phase, caching proves to be a boon as it eliminates the need to repeatedly call the API for the same prompt. This results in faster and more economical development cycles.
- Data Storage : The existence of a comprehensive database that stores all hints simplifies the process of fine-tuning large language models. Leveraging stored prompt-response pairs simplifies model optimization based on accumulated data.
If you want to take caching seriously, you can leverage GPTCache to cache exact and similar match responses. It provides valuable metrics such as cache hit rate, latency, and recall that provide insight into cache performance, enabling continuous optimization to ensure optimal efficiency.
multi-tenant
SaaS software often has multiple tenants and needs to balance simplicity and privacy. For multitenancy of a RAG system, the goal is to build a system that not only finds information efficiently, but also respects the data limitations of each user. In simpler terms, the system isolates each user’s interactions, ensuring that only information relevant to that user is viewed and used.
An easy way to build multi-tenancy is to use metadata. When we add a document to the system, we include specific user information in the metadata. This way, each document is associated with a specific user. When a user searches, this metadata is used to filter to only show documents relevant to that user. It then performs a smart search to find the most important information for that user. This approach prevents private information from being mixed up between different users, keeping everyone’s data safe and private.
Learn how to use Llamaindex to implement multi-tenancy.
Summarize
Building a robust and scalable enterprise-class RAG system obviously requires careful coordination of interconnected components. From user authentication to input guardrails, query rewriting, encoding, document ingestion, and retrieval components such as vector databases and generators, each step plays a critical role in shaping system performance.
We hope this practical guide helps developers and leaders gain actionable insights in the ever-evolving world of RAG systems!