
1. What is LangChain?
LangChain is an open source upper-layer application development framework based on LLM. LangChain provides a series of tools and interfaces that allow developers to easily build and deploy LLM-based applications. LangChain is built around the core concept of “chaining” different components together, simplifying the process of working with LLMs such as GPT-3.5, GPT-4, etc., allowing us to easily create customized advanced use cases.
LangChain has become (one of) the most mainstream frameworks for large model application development. Many AI Hackathon final projects in January 23 used LangChain. Financing of 30 million+ US dollars in 2023 (Sequoia).
Currently, LangChain supports two languages: Python and TypeScript. If you want to experience LangChain, it is recommended to use python language, which is simple and easy to use.
The official website of LangChain is LangChain official website
All use cases and tutorial information can be found here.
2. What problems does LangChain solve?
Through the above concepts, we can see that LangChain is actually an application framework based on the upper layer of the large language model. So what specific problems does LangChain solve in the era of large models that make it stand out? Specifically, it mainly includes the following aspects:
1. Unification of model interfaces
In addition to the well-known ChatGPT, today’s large models also include Meta’s open source LLaMA, Tsinghua University’s GLM, etc. The usage methods of these models, including APIs and inference methods, are very different. If you want to switch from using ChatGPT to calling LLaMA, you need to It takes a lot of effort to develop the front-end model usage module, and there will be a lot of repetitive and tedious work. LangChain encapsulates many common APIs and large models and can be used directly, saving a lot of time.
2. Breaks the limitations of LLM prompt words and returned content tokens, providing greater prospects for the latest knowledge retrieval and reasoning.
For language models like ChatGPT, the data is only updated until 2021. How to let the large model answer and learn future knowledge is a very important question. Moreover, ChatGPT’s API has limitations on prompt words and returned content. 3.5 is 4k, and 4 is 8k. We often need to obtain specific information from our own data and documents, which may be a book, a PDF file, a database with proprietary information. The number of tokens for this information will be much higher than the 4k threshold. It is impossible to obtain the corresponding knowledge by directly using a large model, because the information exceeding the threshold will be truncated.
LangChain provides support for vector databases. It can convert ultra-long txt, pdf, etc. into embedding form through large models, store them in the vector database, and then use the database for retrieval. In this way, inputs of more lengths can be supported, freeing up the advantages of LLM.
3. Basic concepts of LangChain
LangChain can solve two pain points of large models, including complex model interfaces and limited input length, which requires its own carefully designed modules. According to the latest documentation of LangChain, there are currently six core components in LangChain, namely model input and output (Model I/O), data connection (Data Connection), memory (Memory), chains (Chains), and agents ( Agent), callbacks (Callbacks). Below we will describe the functions and functions of each module separately.
Currently, the latest official website has changed the data connection part to retrieval (Retrieval), but the basic content is not much different.
1) Model I/O
Model is the core point of any LLM application. LangChain allows us to easily access various language models and provides many interfaces. It is mainly composed of three components, including models (Models) and prompts (Prompts). and parsers (Output parsers).
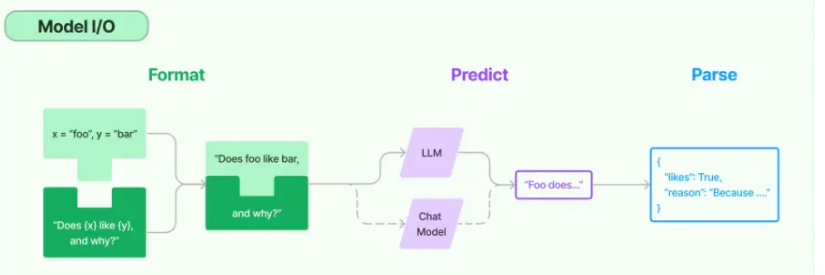
Picture information comes from LangChain official website
1.Models
LangChain provides a variety of different language models, divided by function, there are two main types.
- Language Models (LLMs): What we usually call language models, given an input text, will return a corresponding text. Common language models include GPT3.5, chatglm, GPT4All, etc.
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")
- Chat model: It can be seen as an encapsulated LLM with dialogue capabilities. These models allow you to interact with it in the form of dialogue, and can support chat information as input and return chat information. These chat messages are encapsulated structures, not a simple text string. Common chat models include GPT4, Llama and Llama2, as well as the GPT model related to Microsoft cloud Azure.
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(openai_api_key="...")
2.Prompts
Prompt words are the input of the model, and you can interact with the model by writing prompt words. LangChain provides many templates and functions for modular construction of prompt words. These templates can provide a more flexible method to generate prompt words and have better reusability. Depending on how the model is called, prompt word templates are mainly divided into ordinary templates and chat prompt word templates.
1. Prompt template ( PromptTemplate )
- Prompt templates are a way to generate prompts that contain a template with replaceable content, obtain a set of parameters from the user, and generate the prompt.
- The prompt template is used to generate prompts for LLMs. The simplest usage scenario is, “I hope you will play the role of a code expert and tell me the principle of this method {code}”.
- It is similar to using a dictionary to format strings in python, but it is encapsulated into objects in langchain.
A simple calling example is as follows:
from langchain import PromptTemplate
template = """\
You are a naming consultant for new companies.
What is a good name for a company that makes {product}?
"""
prompt = PromptTemplate.from_template(template)
prompt.format(product="colorful socks")
Output result:
# 实际输出
You are a naming consultant for new companies.
What is a good name for a company that makes colorful socks?
Chat prompt template ( ChatPromptTemplate )
- The chat model receives chat messages as input. These chat messages are usually called Messages. Unlike the original prompt template, these messages are associated with a role.
- When using the chat model, it is recommended to use a chat prompt word template, so that the potential of the chat model can be fully utilized.
A simple usage example is as follows:
from langchain.prompts import (
ChatPromptTemplate,
PromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
template="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
# get a chat completion from the formatted messages
chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_messages()
Output result:
[SystemMessage(content='You are a helpful assistant that translates English to French.', additional_kwargs={}),
HumanMessage(content='I love programming.', additional_kwargs={})]
3.Output parsers
The language model outputs ordinary strings. Sometimes we may want to get a structured representation, such as JSON or CSV. An effective method is to use an output parser.
The output parser is a class that helps build language model output and mainly implements two functions:
- Get the format directive, which is a text string that needs to specify how the output of the language model should be formatted.
- Parsing, a method that accepts a string and parses it into a fixed structure, you can customize the way the string is parsed
A simple usage example is as follows:
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field, validator
from typing import List
model_name = 'text-davinci-003'
temperature = 0.0
model = OpenAI(model_name=model_name, temperature=temperature)
# Define your desired data structure.
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
# You can add custom validation logic easily with Pydantic.
@validator('setup')
def question_ends_with_question_mark(cls, field):
if field[-1] != '?':
raise ValueError("Badly formed question!")
return field
# Set up a parser + inject instructions into the prompt template.
parser = PydanticOutputParser(pydantic_object=Joke)
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
# And a query intended to prompt a language model to populate the data structure.
joke_query = "Tell me a joke."
_input = prompt.format_prompt(query=joke_query)
output = model(_input.to_string())
parser.parse(output)
Output result:
Joke(setup='Why did the chicken cross the road?', punchline='To get to the other side!')
2) Data Connection
Sometimes, we hope that the language model can query from its own data, rather than just relying on itself to output a result. The components of the data connector allow you to use built-in methods to read, modify, store and query your own data. It mainly consists of the following components.
- Document loaders: Connect to different data sources and load documents.
- Document transformers: Defines some common document processing operations, such as splitting documents and discarding useless data
- Text embedding models: Convert unstructured text data into a fixed-dimensional floating point vector
- Vector stores: store and retrieve your vector data
- Retrievers: used to retrieve your data
3)Chains
It is very simple to use only one LLM to develop applications, such as chat robots, but more often, we need to use many LLMs to complete a task together, so the original model is not enough to support such complex applications.
For this reason, LangChain proposed the concept of Chain, which is a sequence of all components that can link independent LLMs into one component, so that more complex tasks can be completed. For example, we can create a chain that receives user input, formats it using prompt word templates, and finally outputs the formatted results to an LLM. Through this chain combination, more and more complex chains can be formed.
There are many well-implemented chains in LangChain. Taking the most basic LLMChain as an example, its main implementation is to receive a prompt word template, then format the user input, then input it into an LLM, and finally return the output of the LLM.
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
LLMChain not only supports llm, but also supports chat llm. The following is a calling example:
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
human_message_prompt = HumanMessagePromptTemplate(
prompt=PromptTemplate(
template="What is a good name for a company that makes {product}?",
input_variables=["product"],
)
)
chat_prompt_template = ChatPromptTemplate.from_messages([human_message_prompt])
chat = ChatOpenAI(temperature=0.9)
chain = LLMChain(llm=chat, prompt=chat_prompt_template)
print(chain.run("colorful socks"))
4) Memory
Most LLM applications will have a conversational interface that allows us to conduct multiple rounds of dialogue with the LLM and has certain context memory capabilities. But in fact, the model itself does not remember any context and can only rely on the user’s own input to generate output. To implement this memory function, additional modules are needed to save the context information of our conversation with the model, and then input all the historical information to the model on the next request, allowing the model to output the final result.
In LangChain, the module that provides this function is called Memory, which is used to store historical information about user and model interactions. In LangChain, there are many different Memory types according to different functions and return values, which can be mainly divided into the following categories:
- Conversation Buffer Memory (ConversationBufferMemory), the most basic memory module, is used to store historical information
- The conversation buffer window memory (ConversationBufferWindowMemory) only saves the last K rounds of conversation information, so this memory space usage will be relatively small.
- Conversation Summary Memory (ConversationSummaryMemory), this mode extracts all historical information, generates summary information, and then saves the summary information as historical information.
- Conversation summary buffer memory (ConversationSummaryBufferMemory), this function is basically the same as the above, but there is a limit on the maximum number of tokens. When the maximum number of tokens is reached, historical information will be merged to generate a summary.
It is worth noting that the starting point for the design of dialogue summary memory is that the context length that the language model can support is limited (usually 2048), and data exceeding this length is naturally truncated . This class will merge according to the turn of the conversation. The default value is 2, which means that LLM will be called every 2 rounds to merge historical information.
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history")
memory.chat_memory.add_user_message("hi!")
memory.chat_memory.add_ai_message("whats up?")
Refer to the official tutorial, Memory supports both LLM and Chat model.
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
# llm
llm = OpenAI(temperature=0)
# Notice that "chat_history" is present in the prompt template
template = """You are a nice chatbot having a conversation with a human.
Previous conversation:
{chat_history}
New human question: {question}
Response:"""
prompt = PromptTemplate.from_template(template)
# Notice that we need to align the `memory_key`
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
conversation({"question": "hi"})
The following is an example of using Chat model to call Memory.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# The `variable_name` here is what must align with memory
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
conversation({"question": "hi"})
5) Agents
The core idea of agent is to use LLM to select the user’s input and which specific tool should be used to operate it. The tool here can be another LLM, a function or a chain. In the agent module, there are three core concepts.
1. Agent, relying on a powerful language model and prompt words, the agent is used to decide what to do next, and its core is to build an excellent prompt word. This prompt word generally has the following functions:
- Role definition, giving the agent an identity that suits him/herself
- Contextual information, providing him with more information to ask him what tasks he can perform
- Rich prompt strategies to increase the agent’s reasoning ability
2. Tools. Agents will choose different tools to perform different tasks. Tools mainly provide agents with methods to call themselves and describe how they are used. These two aspects of tools are very important. If you do not provide a method to call the tool, the agent will never complete its task; at the same time, if the tool is not described correctly, the agent will not know how to use the tool.
3. Toolkits. LangChain provides the use of toolkits. A toolkit usually contains 3-5 tools.
Agent technology is currently a frontier and hot topic in large language model research. However, currently limited by the actual effect of large models, only GPT 4.0 can effectively carry out Agent-related research. We believe that in the future, with the optimization and iteration of large model performance, Agent technology should have better development and prospects.
6) Callbacks
Callback, the literal explanation is to let the system call the function we specified. LangChain provides such a callback system, allowing you to perform log printing, monitoring, streaming and other tasks. The callback function can be easily implemented by providing callback parameters directly in the API. LangChain has many built-in objects that can implement callback functions. We usually call them handlers, which are used to define the functions that can be implemented when different events are triggered.
Regardless of whether you use Chains, Models, Tools, or Agents, to call handlers, you always use the callbacks parameter. This parameter can be used in two different places:
- constructor, but its scope can only be the object. For example, the constructor of LLMChain below can perform callbacks, but this callback function is not effective for the LLM model linked to it.
LLMChain(callbacks=[handler], tags=['a-tag'])
- When called in the run()/apply() method, only the current request will respond to this callback function, but all subrequests included in the current request will call this callback. For example, if a chain is used to trigger this request, the LLM model connected to it will also call this callback.
chain.run(input, callbacks=[handler])
4. Advantages of LangChain
LLM application development framework similar to LangChain:
- OpenAI’s GPT-3.5/4 API
- Hugging Face’s Transformers (multimodal machine learning model, supports thousands of pre-trained models)
- Google’s T5 (NLP framework), etc.
Advantages of LangChain:
- More capable, updated by days
- The code design is elegant and modular. The Chain, Agent, and Memory modules have a high level of abstraction and are easy to combine and apply.
- Complete integrated tools, ranging from data preprocessing, LLM model, vectorization, graph database, etc.
- Supports commonly used LLM and a large number of commercial NLP models
- Commercialization: Azure OpenAI, OpenAI
- Open source: Hugging Face, GPT4All
- There are tons of LLM use cases for reference
5. Applications based on LangChain
From the above, we understand the basic concepts and main components of LangChain. Using these can help us quickly get started building apps. LangChain can be applied in many usage scenarios, including but not limited to:
- Personal assistants and chatbots; able to remember every interaction with you and personalize it
- Document-based question answering system; answering questions on specific documents can reduce the hallucination problem of large models
- Table data query; provides query function for structured data, such as CSV, PDF, SQL, DataFrame, etc.
- API interaction; can connect to APIs of different language models and generate interactions and calls
- Information extraction; extract structured information from text and output
- Document summary; use LLM and embedding to compress and summarize long documents
And there are also many people on github who have open sourced open source applications developed based on LangChain:
6. Disadvantages of LangChain
In terms of actual user experience, this is not a perfect framework and there are many problems.
For example, LangChain’s prompt word template is actually a class that encapsulates a string. However, there are many types of prompt word templates in LangChain. There is no obvious difference, and there is no security, and there are many redundancies. Moreover, some promotion words are written by default. If you want to modify them, you need to look at the source code to know what should be modified.
LangChain encapsulates many calling processes internally, and the debugging process is difficult. Once a problem occurs, troubleshooting may take a long time.
It has been previously reported that LangChain’s code will have security vulnerabilities when calling python to execute the agent, which may cause danger through injection attacks. However, these similar loopholes need to be fixed by the official, which will bring unnecessary trouble to our development.
LangChain’s documentation is too simple. If you want to implement some methods that are not officially provided, you need to use some brains.
Summarize
As an emerging open source LLM development framework, LangChain’s design concepts and some implementation methods are worth learning from. Of course, an open source project must have its own advantages and many shortcomings. When we actually use it, we should choose according to our own needs and actual conditions . Remember not to make a choice simply because of online reviews. After all, only you know whether it works or not.